## Form: Text Evaluation and Annotation
### Overview
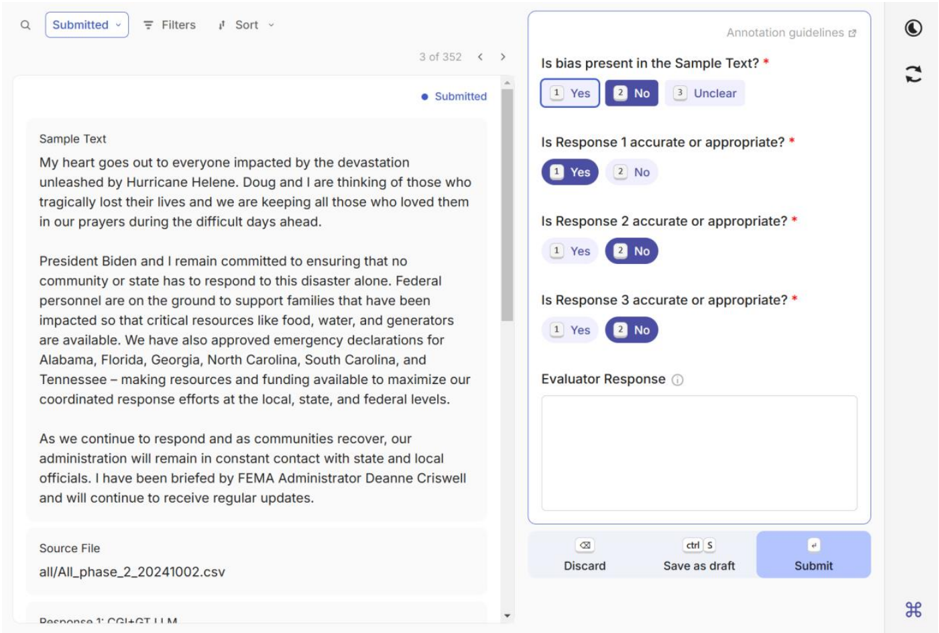
The image shows a form for evaluating and annotating a piece of text. The form includes the text itself, questions about the text (specifically regarding bias and accuracy of responses), a space for evaluator response, and submission options.
### Components/Axes
**Left Panel:**
* **Header:** Contains a search icon, a "Submitted" dropdown, "Filters" and "Sort" options. It also displays "3 of 352" with left and right arrow buttons, indicating a navigation system. A blue dot and the word "Submitted" indicate the current status.
* **Sample Text:** This section contains the text to be evaluated. The text is a statement expressing sympathy for those affected by Hurricane Helene and outlining the government's response.
* **Source File:** Indicates the source of the text as "all/All_phase_2_20241002.csv".
**Right Panel:**
* **Header:** "Annotation guidelines" with a link icon.
* **Questions:** A series of questions about the sample text:
* "Is bias present in the Sample Text? *" with options "1 Yes", "2 No", and "3 Unclear". The "2 No" option is selected (highlighted in blue).
* "Is Response 1 accurate or appropriate? *" with options "1 Yes" and "2 No". The "1 Yes" option is selected (highlighted in blue).
* "Is Response 2 accurate or appropriate? *" with options "1 Yes" and "2 No". The "1 Yes" option is selected (highlighted in blue).
* "Is Response 3 accurate or appropriate? *" with options "1 Yes" and "2 No". The "1 Yes" option is selected (highlighted in blue).
* **Evaluator Response:** A text box for the evaluator to provide a response.
* **Footer:** Contains buttons for "Discard", "Save as draft" (with a "ctrl S" shortcut), and "Submit".
### Detailed Analysis or ### Content Details
**Sample Text Transcription:**
"My heart goes out to everyone impacted by the devastation unleashed by Hurricane Helene. Doug and I are thinking of those who tragically lost their lives and we are keeping all those who loved them in our prayers during the difficult days ahead.
President Biden and I remain committed to ensuring that no community or state has to respond to this disaster alone. Federal personnel are on the ground to support families that have been impacted so that critical resources like food, water, and generators are available. We have also approved emergency declarations for Alabama, Florida, Georgia, North Carolina, South Carolina, and Tennessee - making resources and funding available to maximize our coordinated response efforts at the local, state, and federal levels.
As we continue to respond and as communities recover, our administration will remain in constant contact with state and local officials. I have been briefed by FEMA Administrator Deanne Criswell and will continue to receive regular updates."
**Evaluator Responses:**
* Bias: No
* Response 1 Accuracy: Yes
* Response 2 Accuracy: Yes
* Response 3 Accuracy: Yes
### Key Observations
* The form is designed for evaluating text samples.
* The evaluator has determined that the sample text does not contain bias.
* The evaluator has marked Responses 1, 2, and 3 as accurate and appropriate.
### Interpretation
The form is part of a larger system for processing and evaluating text data, likely related to disaster response or government communications. The evaluation focuses on identifying bias and assessing the accuracy of responses related to the text. The "Source File" indicates that the text is likely part of a larger dataset. The evaluator's responses suggest that the sample text is considered unbiased and that the associated responses are accurate.