## Game Evaluation: Mastermind with Agentic and Deductive Reasoning
### Overview
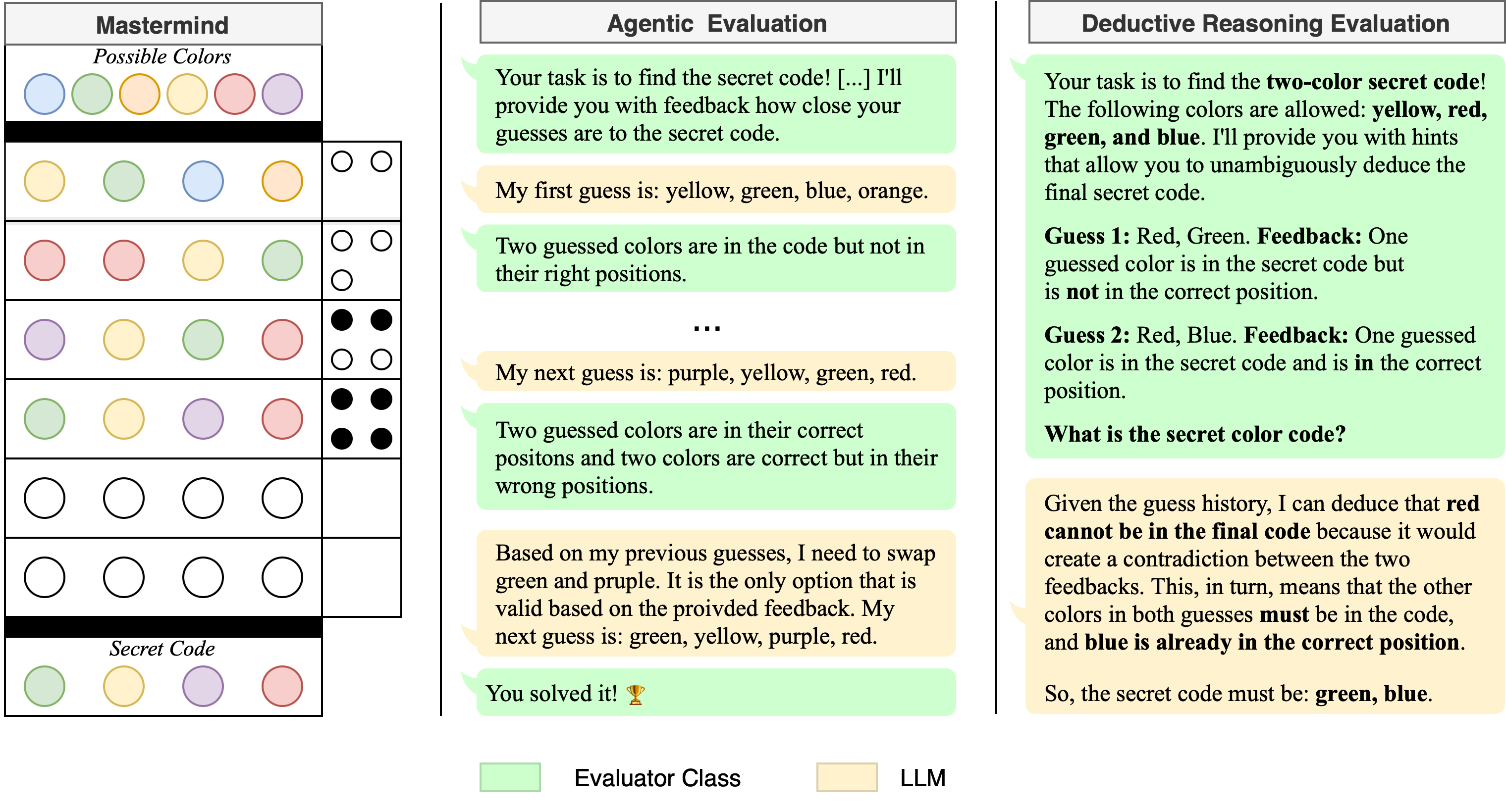
The image presents three distinct sections: a Mastermind game board, an "Agentic Evaluation" of a game-playing AI, and a "Deductive Reasoning Evaluation" of another AI. The Mastermind section shows a game in progress. The Agentic Evaluation shows an AI attempting to solve the Mastermind game. The Deductive Reasoning Evaluation shows an AI attempting to solve a simplified two-color Mastermind game using deductive logic.
### Components/Axes
**Mastermind Section (Left)**
* **Title:** Mastermind
* **Subtitle:** Possible Colors
* Colors: Blue, Green, Yellow, Orange, Red, Purple
* **Game Board:**
* Rows 1-4: Guesses with feedback.
* Row 5-6: Empty guesses.
* Row 7: Secret Code.
* **Feedback Mechanism:** Black and white dots indicating correct color and position.
* **Secret Code:** Green, Yellow, Purple, Red
**Agentic Evaluation Section (Center)**
* **Title:** Agentic Evaluation
* **Content:** A series of text blocks representing the AI's thought process and guesses.
* **Color Coding:** Green for "Evaluator Class" and Yellow for "LLM" (Language Learning Model).
**Deductive Reasoning Evaluation Section (Right)**
* **Title:** Deductive Reasoning Evaluation
* **Content:** A series of text blocks representing the AI's deductive reasoning process.
* **Color Coding:** Green for "Evaluator Class" and Yellow for "LLM" (Language Learning Model).
**Legend (Bottom)**
* Evaluator Class: Green
* LLM: Yellow
### Detailed Analysis
**Mastermind Game Board**
* **Possible Colors:** The top row displays the possible colors for the game: blue, green, yellow, orange, red, and purple.
* **Guess 1:** Yellow, Green, Blue, Orange. Feedback: Two white dots, indicating two colors are correct but in the wrong position.
* **Guess 2:** Red, Red, Red, Red. Feedback: Four black dots, indicating four colors are correct and in the correct position.
* **Guess 3:** Purple, Yellow, Green, Red. Feedback: Four black dots, indicating four colors are correct and in the correct position.
* **Guess 4:** Green, Yellow, Purple, Red. Feedback: Four black dots, indicating four colors are correct and in the correct position.
* **Secret Code:** The secret code is revealed to be Green, Yellow, Purple, Red.
**Agentic Evaluation**
The AI's thought process is presented as a series of statements:
* **Initial Task:** The AI is tasked with finding the secret code and will receive feedback on its guesses.
* **First Guess:** Yellow, Green, Blue, Orange.
* **Feedback:** Two guessed colors are in the code but not in their right positions.
* **Next Guess:** Purple, Yellow, Green, Red.
* **Feedback:** Two guessed colors are in their correct positions and two colors are correct but in their wrong positions.
* **Deduction:** Based on previous guesses, the AI needs to swap green and purple.
* **Next Guess:** Green, Yellow, Purple, Red.
* **Result:** The AI solves the game.
**Deductive Reasoning Evaluation**
The AI's deductive reasoning process is presented as a series of statements:
* **Initial Task:** The AI is tasked with finding the two-color secret code, with allowed colors being yellow, red, green, and blue.
* **Guess 1:** Red, Green. Feedback: One guessed color is in the secret code but is not in the correct position.
* **Guess 2:** Red, Blue. Feedback: One guessed color is in the secret code and is in the correct position.
* **Deduction:** Red cannot be in the final code. The other colors in both guesses (green and blue) must be in the code, and blue is already in the correct position.
* **Solution:** The secret code is green, blue.
### Key Observations
* The Mastermind game is successfully solved in four guesses.
* The Agentic Evaluation demonstrates an AI's ability to solve the Mastermind game through iterative guessing and feedback analysis.
* The Deductive Reasoning Evaluation showcases an AI's ability to solve a simplified Mastermind game using logical deduction.
### Interpretation
The image illustrates different approaches to solving the Mastermind game. The Mastermind game board shows a human-like approach, while the Agentic Evaluation and Deductive Reasoning Evaluation demonstrate AI-driven solutions. The Agentic Evaluation highlights the use of feedback to refine guesses, while the Deductive Reasoning Evaluation emphasizes logical deduction to arrive at the solution. The comparison provides insights into the strengths and weaknesses of different problem-solving strategies.