## Image Description
### Overview
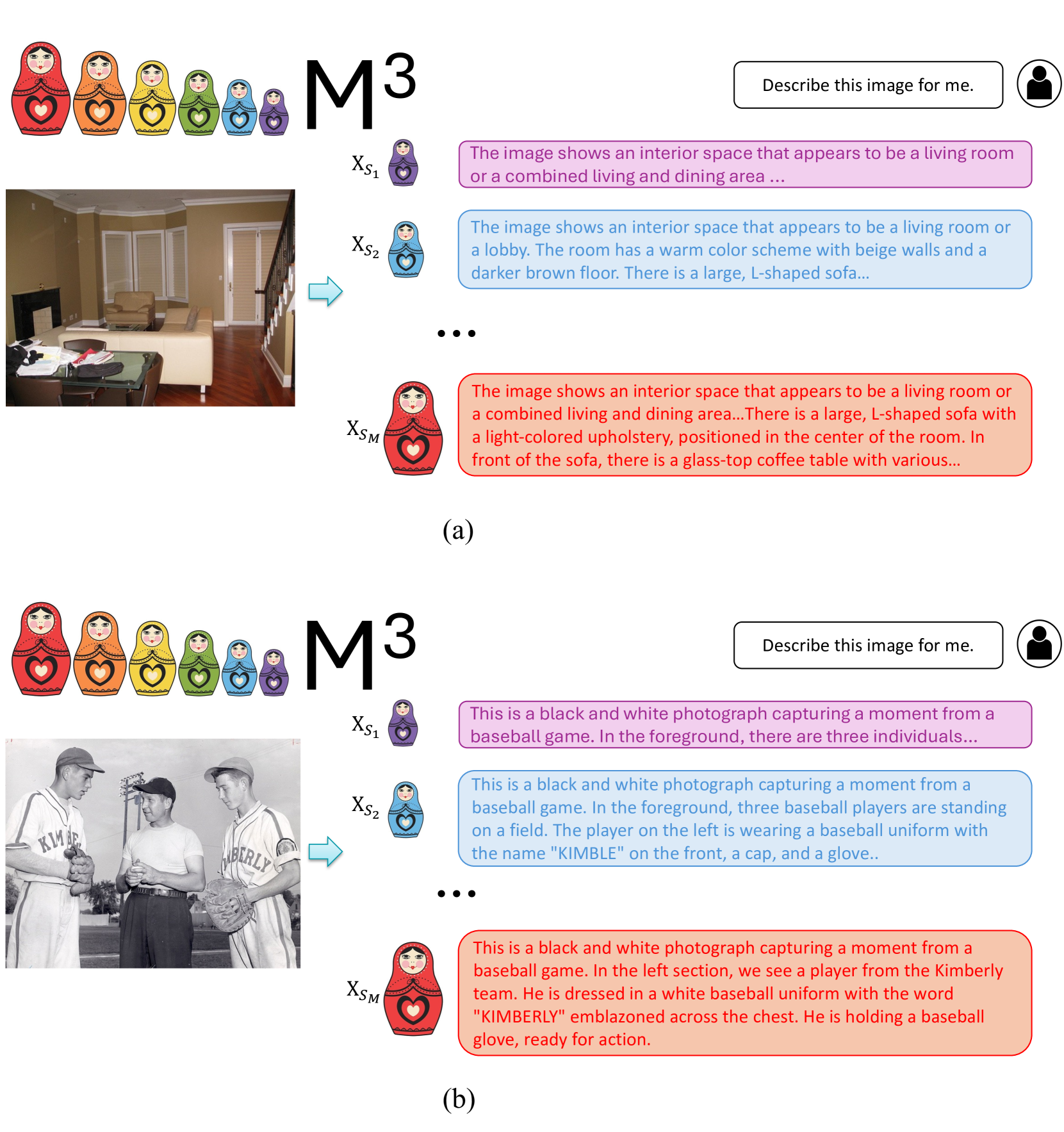
The image consists of two sections labeled (a) and (b). Both sections contain a series of colorful Russian nesting dolls, each labeled with a different color and a corresponding text box with a brief description.
### Components/Axes
- **Russian Nesting Dolls**: There are seven dolls in total, each with a different color and a heart symbol on the chest.
- **Text Boxes**: Each doll is associated with a text box that provides a brief description of the image.
- **Labels**: The dolls are labeled with colors: red, orange, yellow, green, blue, purple, and pink.
- **Axis Titles**: There are no axis titles visible in the image.
### Detailed Analysis or ### Content Details
- **Section (a)**:
- The dolls are arranged in a row, with the red doll at the front and the pink doll at the back.
- The text box next to the red doll reads: "The image shows an interior space that appears to be a living room or a combined living and dining area."
- The text box next to the orange doll reads: "The image shows an interior space that appears to be a living room or a combined living and dining area. The room has a warm color scheme with beige walls and a darker brown floor."
- The text box next to the yellow doll reads: "The image shows an interior space that appears to be a living room or a combined living and dining area. There is a large, L-shaped sofa with a light-colored upholstery, positioned in the center of the room."
- The text box next to the green doll reads: "The image shows an interior space that appears to be a living room or a combined living and dining area. In front of the sofa, there is a glass-top coffee table with various..."
- The text box next to the blue doll reads: "The image shows an interior space that appears to be a living room or a combined living and dining area. There is a large, L-shaped sofa with a light-colored upholstery, positioned in the center of the room. In front of the sofa, there is a glass-top coffee table with various..."
- The text box next to the purple doll reads: "The image shows an interior space that appears to be a living room or a combined living and dining area. There is a large, L-shaped sofa with a light-colored upholstery, positioned in the center of the room. In front of the sofa, there is a glass-top coffee table with various..."
- The text box next to the pink doll reads: "The image shows an interior space that appears to be a living room or a combined living and dining area. There is a large, L-shaped sofa with a light-colored upholstery, positioned in the center of the room. In front of the sofa, there is a glass-top coffee table with various..."
- **Section (b)**:
- The dolls are arranged in a row, with the red doll at the front and the pink doll at the back.
- The text box next to the red doll reads: "This is a black and white photograph capturing a moment from a baseball game. In the foreground, there are three individuals..."
- The text box next to the orange doll reads: "This is a black and white photograph capturing a moment from a baseball game. In the foreground, three baseball players are standing on a field. The player on the left is wearing a baseball uniform with the name 'KIMBLY' on the front, a cap, and a glove..."
- The text box next to the yellow doll reads: "This is a black and white photograph capturing a moment from a baseball game. In the left section, we see a player from the Kimberly team. He is dressed in a white baseball uniform with the word 'KIMBLY' emblazoned across the chest. He is holding a baseball glove, ready for action."
- The text box next to the green doll reads: "This is a black and white photograph capturing a moment from a baseball game. In the foreground, three baseball players are standing on a field. The player on the left is wearing a baseball uniform with the name 'KIMBLY' on the front, a cap, and a glove..."
- The text box next to the blue doll reads: "This is a black and white photograph capturing a moment from a baseball game. In the left section, we see a player from the Kimberly team. He is dressed in a white baseball uniform with the word 'KIMBLY' emblazoned across the chest. He is holding a baseball glove, ready for action."
- The text box next to the purple doll reads: "This is a black and white photograph capturing a moment from a baseball game. In the foreground, three baseball players are standing on a field. The player on the left is wearing a baseball uniform with the name 'KIMBLY' on the front, a cap, and a glove..."
- The text box next to the pink doll reads: "This is a black and white photograph capturing a moment from a baseball game. In the left section, we see a player from the Kimberly team. He is dressed in a white baseball uniform with the word 'KIMBLY' emblazoned across the chest. He is holding a baseball glove, ready for action."
### Key Observations
- The dolls are arranged in a row, with the red doll at the front and the pink doll at the back.
- The text boxes provide detailed descriptions of the interior spaces and the baseball game.
- The dolls are labeled with colors, and each label corresponds to a text box with a brief description.
### Interpretation
The image is a creative representation of a series of Russian nesting dolls, each labeled with a different color and a corresponding text box with a brief description. The dolls are arranged in a row, with the red doll at the front and the pink doll at the back. The text boxes provide detailed descriptions of the interior spaces and the baseball game. The dolls are labeled with colors, and each label corresponds to a text box with a brief description. The image is a creative representation of a series of Russian nesting dolls, each labeled with a different color and a corresponding text box with a brief description. The dolls are arranged in a row, with the red doll at the front and the pink doll at the back. The text boxes provide detailed descriptions of the interior spaces and the baseball game. The dolls are labeled with colors, and each label corresponds to a text box with a brief description.