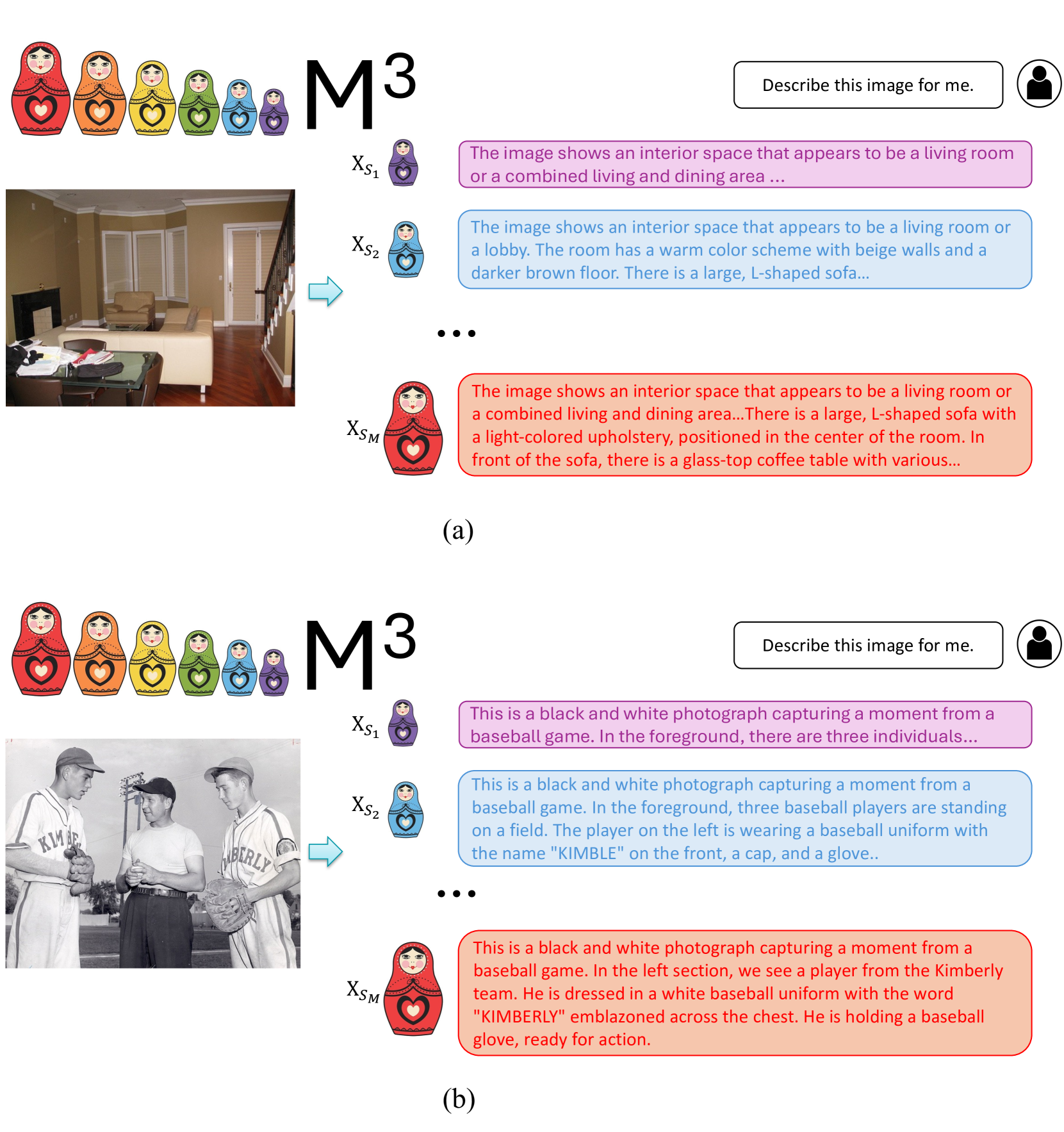
# Technical Document Extraction: Matryoshka Multimodal Models ($M^3$) Diagram
This document describes a technical figure illustrating a multimodal AI architecture, likely titled or referred to as **$M^3$**. The image is divided into two primary horizontal sections, labeled **(a)** and **(b)**, representing different input examples processed by the same system logic.
---
## 1. Global Components (Common to both (a) and (b))
### Header/Logo Section
* **Visual Icon:** A set of six Matryoshka (nesting) dolls arranged from largest to smallest. The colors from largest to smallest are: Red, Orange, Yellow, Green, Blue, and Purple.
* **Text Label:** Large bold text reading **$M^3$**.
* **User Input Box:** Located at the top right, containing a user icon and a speech bubble with the text: `"Describe this image for me."`
### Processing Flow
* **Input Image:** A source image is provided on the left.
* **Transformation Arrow:** A light blue arrow points from the input image toward a series of output levels.
* **Scale Indicators ($X_{S_n}$):** Three specific scales are highlighted, each associated with a Matryoshka doll of a specific size and color:
* **$X_{S_1}$**: Associated with the smallest **Purple** doll.
* **$X_{S_2}$**: Associated with the second-smallest **Blue** doll.
* **$X_{S_M}$**: Associated with the largest **Red** doll.
* **Ellipsis (...):** Vertical dots between $X_{S_2}$ and $X_{S_M}$ indicate intermediate scales not explicitly shown.
---
## 2. Section (a) Analysis: Interior Scene
### Input Image (a)
A color photograph of a living room featuring beige walls, a large L-shaped cream-colored sofa, a glass-top coffee table, and a dark wood floor.
### Output Text Blocks (a)
* **Purple Level ($X_{S_1}$):** "The image shows an interior space that appears to be a living room or a combined living and dining area ..."
* **Blue Level ($X_{S_2}$):** "The image shows an interior space that appears to be a living room or a lobby. The room has a warm color scheme with beige walls and a darker brown floor. There is a large, L-shaped sofa..."
* **Red Level ($X_{S_M}$):** "The image shows an interior space that appears to be a living room or a combined living and dining area...There is a large, L-shaped sofa with a light-colored upholstery, positioned in the center of the room. In front of the sofa, there is a glass-top coffee table with various..."
---
## 3. Section (b) Analysis: Baseball Scene
### Input Image (b)
A black and white photograph of three men on a baseball field. Two players are wearing uniforms with "KIMBERLY" or "KIMBE" text, and one man in the center is wearing a t-shirt and cap.
### Output Text Blocks (b)
* **Purple Level ($X_{S_1}$):** "This is a black and white photograph capturing a moment from a baseball game. In the foreground, there are three individuals..."
* **Blue Level ($X_{S_2}$):** "This is a black and white photograph capturing a moment from a baseball game. In the foreground, three baseball players are standing on a field. The player on the left is wearing a baseball uniform with the name \"KIMBLE\" on the front, a cap, and a glove.."
* **Red Level ($X_{S_M}$):** "This is a black and white photograph capturing a moment from a baseball game. In the left section, we see a player from the Kimberly team. He is dressed in a white baseball uniform with the word \"KIMBERLY\" emblazoned across the chest. He is holding a baseball glove, ready for action."
---
## 4. Key Trends and Observations
* **Granularity Scaling:** As the Matryoshka doll size increases (from $X_{S_1}$ Purple to $X_{S_M}$ Red), the descriptive text becomes significantly more detailed and specific.
* **Information Density:**
* **Smallest Scale ($X_{S_1}$):** Provides a high-level summary/gist.
* **Medium Scale ($X_{S_2}$):** Adds environmental details (colors, specific furniture types, partial text recognition).
* **Largest Scale ($X_{S_M}$):** Provides comprehensive descriptions, including textures, precise positioning, and full text extraction (e.g., correcting "KIMBE" to "KIMBERLY").
* **System Logic:** The diagram demonstrates a "Matryoshka" approach to multimodal embeddings or generation, where different "scales" of the model provide varying levels of descriptive depth for the same input.