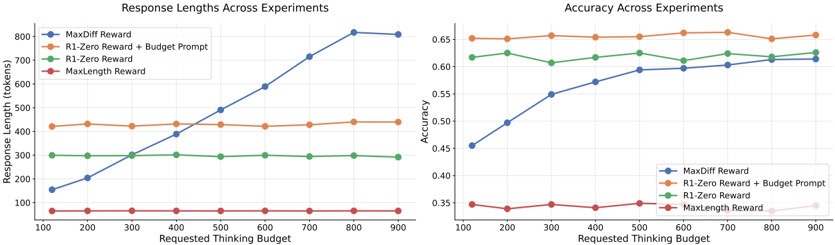
## Chart: Response Lengths and Accuracy Across Experiments
### Overview
The image presents two line charts comparing the performance of different reward mechanisms (MaxDiff Reward, R1-Zero Reward + Budget Prompt, R1-Zero Reward, and MaxLength Reward) across varying "Requested Thinking Budgets." The left chart displays "Response Length (tokens)," while the right chart shows "Accuracy."
### Components/Axes
**Left Chart: Response Lengths Across Experiments**
* **Title:** Response Lengths Across Experiments
* **Y-axis:** Response Length (tokens)
* Scale: 100 to 800, incrementing by 100.
* **X-axis:** Requested Thinking Budget
* Scale: 100 to 900, incrementing by 100.
* **Legend:** Located in the top-left corner.
* Blue: MaxDiff Reward
* Orange: R1-Zero Reward + Budget Prompt
* Green: R1-Zero Reward
* Red: MaxLength Reward
**Right Chart: Accuracy Across Experiments**
* **Title:** Accuracy Across Experiments
* **Y-axis:** Accuracy
* Scale: 0.35 to 0.65, incrementing by 0.05.
* **X-axis:** Requested Thinking Budget
* Scale: 100 to 900, incrementing by 100.
* **Legend:** Located in the bottom-left corner.
* Blue: MaxDiff Reward
* Orange: R1-Zero Reward + Budget Prompt
* Green: R1-Zero Reward
* Red: MaxLength Reward
### Detailed Analysis
**Left Chart: Response Lengths Across Experiments**
* **MaxDiff Reward (Blue):** The line slopes upward significantly from approximately 150 tokens at a budget of 100 to approximately 810 tokens at a budget of 800, then plateaus at approximately 810 tokens at a budget of 900.
* (100, 150)
* (200, 200)
* (300, 280)
* (400, 390)
* (500, 490)
* (600, 610)
* (700, 720)
* (800, 810)
* (900, 810)
* **R1-Zero Reward + Budget Prompt (Orange):** The line is relatively flat, fluctuating slightly around 420 tokens across all budget levels.
* (100, 420)
* (200, 420)
* (300, 430)
* (400, 420)
* (500, 420)
* (600, 420)
* (700, 420)
* (800, 420)
* (900, 420)
* **R1-Zero Reward (Green):** The line is relatively flat, fluctuating slightly around 290 tokens across all budget levels.
* (100, 290)
* (200, 290)
* (300, 290)
* (400, 290)
* (500, 290)
* (600, 290)
* (700, 290)
* (800, 300)
* (900, 290)
* **MaxLength Reward (Red):** The line is relatively flat, fluctuating slightly around 70 tokens across all budget levels.
* (100, 70)
* (200, 70)
* (300, 70)
* (400, 70)
* (500, 70)
* (600, 70)
* (700, 70)
* (800, 70)
* (900, 70)
**Right Chart: Accuracy Across Experiments**
* **MaxDiff Reward (Blue):** The line slopes upward from approximately 0.45 at a budget of 100 to approximately 0.60 at a budget of 800, then plateaus at approximately 0.60 at a budget of 900.
* (100, 0.45)
* (200, 0.49)
* (300, 0.55)
* (400, 0.58)
* (500, 0.59)
* (600, 0.59)
* (700, 0.60)
* (800, 0.60)
* (900, 0.60)
* **R1-Zero Reward + Budget Prompt (Orange):** The line is relatively flat, fluctuating slightly around 0.65 across all budget levels.
* (100, 0.65)
* (200, 0.65)
* (300, 0.65)
* (400, 0.65)
* (500, 0.65)
* (600, 0.65)
* (700, 0.66)
* (800, 0.65)
* (900, 0.66)
* **R1-Zero Reward (Green):** The line is relatively flat, fluctuating slightly around 0.62 across all budget levels.
* (100, 0.62)
* (200, 0.61)
* (300, 0.61)
* (400, 0.62)
* (500, 0.62)
* (600, 0.61)
* (700, 0.62)
* (800, 0.62)
* (900, 0.62)
* **MaxLength Reward (Red):** The line is relatively flat, fluctuating slightly around 0.35 across all budget levels.
* (100, 0.34)
* (200, 0.34)
* (300, 0.35)
* (400, 0.34)
* (500, 0.35)
* (600, 0.34)
* (700, 0.34)
* (800, 0.34)
* (900, 0.35)
### Key Observations
* **Response Length:** The MaxDiff Reward mechanism shows a significant increase in response length as the requested thinking budget increases, while the other mechanisms maintain relatively constant response lengths.
* **Accuracy:** The R1-Zero Reward + Budget Prompt mechanism consistently achieves the highest accuracy across all budget levels. The MaxDiff Reward mechanism shows an increase in accuracy with an increasing budget, but it plateaus. The MaxLength Reward mechanism consistently has the lowest accuracy.
* **Trade-off:** There appears to be a trade-off between response length and accuracy. The MaxDiff Reward mechanism increases response length but does not achieve the highest accuracy. The MaxLength Reward mechanism produces the shortest responses but also the lowest accuracy.
### Interpretation
The data suggests that the choice of reward mechanism significantly impacts both the response length and accuracy of the model. The MaxDiff Reward mechanism encourages longer responses as the thinking budget increases, which may be beneficial in some contexts. However, the R1-Zero Reward + Budget Prompt mechanism consistently achieves the highest accuracy, suggesting it may be the most effective for generating accurate responses. The MaxLength Reward mechanism appears to be the least effective, as it produces short and inaccurate responses.
The relationship between response length and accuracy is complex and depends on the specific task and reward mechanism. In this case, simply increasing the response length does not necessarily lead to higher accuracy. The R1-Zero Reward + Budget Prompt mechanism seems to strike a better balance between response length and accuracy.