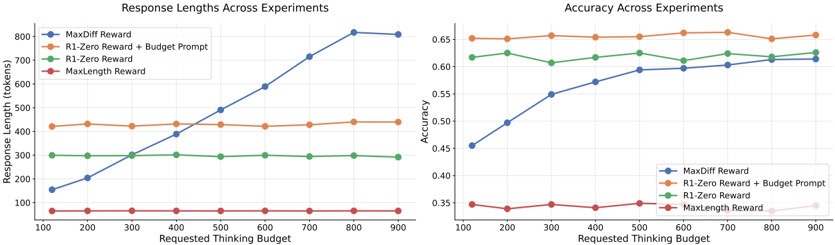
## Charts: Response Length and Accuracy Across Experiments
### Overview
The image presents two line charts side-by-side. The left chart displays "Response Lengths Across Experiments" with response length in tokens on the y-axis and requested thinking budget on the x-axis. The right chart shows "Accuracy Across Experiments" with accuracy on the y-axis and requested thinking budget on the x-axis. Both charts compare the performance of different reward strategies.
### Components/Axes
**Left Chart (Response Length):**
* **Title:** Response Lengths Across Experiments
* **X-axis Label:** Requested Thinking Budget (ranging from 100 to 900, with markers at 100, 200, 300, 400, 500, 600, 700, 800, 900)
* **Y-axis Label:** Response Length (tokens) (ranging from 0 to 800, with markers at 100, 200, 300, 400, 500, 600, 700, 800)
* **Legend:**
* MaxDiff Reward (Blue)
* R1-Zero Reward + Budget Prompt (Orange)
* R1-Zero Reward (Green)
* MaxLength Reward (Red)
**Right Chart (Accuracy):**
* **Title:** Accuracy Across Experiments
* **X-axis Label:** Requested Thinking Budget (ranging from 100 to 900, with markers at 100, 200, 300, 400, 500, 600, 700, 800, 900)
* **Y-axis Label:** Accuracy (ranging from 0.30 to 0.70, with markers at 0.35, 0.40, 0.45, 0.50, 0.55, 0.60, 0.65, 0.70)
* **Legend:**
* MaxDiff Reward (Blue)
* R1-Zero Reward + Budget Prompt (Orange)
* R1-Zero Reward (Green)
* MaxLength Reward (Red)
### Detailed Analysis or Content Details
**Left Chart (Response Length):**
* **MaxDiff Reward (Blue):** The line slopes sharply upward, starting at approximately 300 tokens at a budget of 100, and reaching approximately 800 tokens at a budget of 900.
* **R1-Zero Reward + Budget Prompt (Orange):** The line is relatively flat, starting at approximately 450 tokens at a budget of 100, and remaining around 450-500 tokens throughout the budget range, ending at approximately 475 tokens at a budget of 900.
* **R1-Zero Reward (Green):** The line is nearly flat, starting at approximately 425 tokens at a budget of 100, and remaining around 425-450 tokens throughout the budget range, ending at approximately 425 tokens at a budget of 900.
* **MaxLength Reward (Red):** The line is almost perfectly flat, remaining around 100 tokens throughout the budget range, ending at approximately 100 tokens at a budget of 900.
**Right Chart (Accuracy):**
* **MaxDiff Reward (Blue):** The line slopes upward, starting at approximately 0.43 at a budget of 100, and reaching approximately 0.63 at a budget of 900.
* **R1-Zero Reward + Budget Prompt (Orange):** The line fluctuates around 0.65, starting at approximately 0.68 at a budget of 100, dipping to approximately 0.63 at a budget of 400, and ending at approximately 0.65 at a budget of 900.
* **R1-Zero Reward (Green):** The line fluctuates around 0.62, starting at approximately 0.63 at a budget of 100, dipping to approximately 0.60 at a budget of 400, and ending at approximately 0.62 at a budget of 900.
* **MaxLength Reward (Red):** The line is relatively flat, starting at approximately 0.35 at a budget of 100, and remaining around 0.35-0.40 throughout the budget range, ending at approximately 0.37 at a budget of 900.
### Key Observations
* The MaxDiff Reward strategy results in significantly longer responses as the thinking budget increases.
* The MaxLength Reward strategy produces consistently short responses, regardless of the thinking budget.
* Accuracy generally increases with the thinking budget for the MaxDiff Reward strategy.
* The R1-Zero Reward and R1-Zero Reward + Budget Prompt strategies show relatively stable accuracy and response length across different thinking budgets.
* The MaxLength Reward strategy consistently exhibits the lowest accuracy.
### Interpretation
The data suggests that increasing the thinking budget has a substantial impact on the length of responses generated by the MaxDiff Reward strategy, while having a moderate impact on its accuracy. The MaxLength Reward strategy prioritizes brevity over accuracy, resulting in short responses with consistently low accuracy. The R1-Zero Reward strategies offer a balance between response length and accuracy, with relatively stable performance across different thinking budgets.
The relationship between the two charts is clear: as response length increases (driven by the MaxDiff Reward), accuracy also tends to increase. This suggests that allowing the model more "thinking time" (through a higher budget) and rewarding differentiation (MaxDiff) leads to more informative and accurate responses, but at the cost of increased token usage. The other strategies demonstrate that simply increasing the budget does not necessarily improve accuracy if the reward function doesn't incentivize it. The flat lines for R1-Zero strategies suggest a limited capacity to benefit from increased budget under those reward schemes. The MaxLength strategy shows that constraining response length severely impacts accuracy.
Anomalies are not readily apparent, but the slight fluctuations in the R1-Zero Reward strategies could warrant further investigation to understand the factors influencing those variations.