\n
## Line Charts: Response Lengths and Accuracy Across Experiments
### Overview
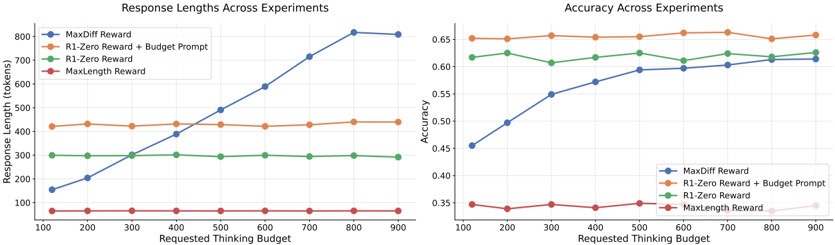
The image displays two side-by-side line charts comparing the performance of four different reward methods ("MaxDiff Reward", "R1-Zero Reward + Budget Prompt", "R1-Zero Reward", "MaxLength Reward") across a range of "Requested Thinking Budget" values. The left chart tracks the resulting response length in tokens, while the right chart tracks the accuracy of the responses.
### Components/Axes
**Shared Elements:**
* **X-Axis (Both Charts):** Labeled "Requested Thinking Budget". The scale runs from 100 to 900 in increments of 100.
* **Legend (Both Charts):** Located in the top-left corner of each chart's plot area. It defines four data series:
* **MaxDiff Reward:** Blue line with circular markers.
* **R1-Zero Reward + Budget Prompt:** Orange line with circular markers.
* **R1-Zero Reward:** Green line with circular markers.
* **MaxLength Reward:** Red line with circular markers.
**Left Chart: Response Lengths Across Experiments**
* **Title:** "Response Lengths Across Experiments"
* **Y-Axis:** Labeled "Response Length (tokens)". The scale runs from 0 to 800 in increments of 100.
**Right Chart: Accuracy Across Experiments**
* **Title:** "Accuracy Across Experiments"
* **Y-Axis:** Labeled "Accuracy". The scale runs from 0.35 to 0.65 in increments of 0.05.
### Detailed Analysis
**Left Chart - Response Length Trends:**
1. **MaxDiff Reward (Blue):** Shows a strong, nearly linear upward trend. It starts at approximately 150 tokens at a budget of 100 and increases steadily to approximately 800 tokens at a budget of 900.
2. **R1-Zero Reward + Budget Prompt (Orange):** Exhibits a flat trend. The response length remains stable at approximately 450 tokens across all thinking budget values from 100 to 900.
3. **R1-Zero Reward (Green):** Also exhibits a flat trend. The response length remains stable at approximately 300 tokens across all thinking budget values.
4. **MaxLength Reward (Red):** Exhibits a flat trend at the lowest level. The response length remains stable at approximately 100 tokens across all thinking budget values.
**Right Chart - Accuracy Trends:**
1. **MaxDiff Reward (Blue):** Shows a strong upward trend. Accuracy starts at approximately 0.45 at a budget of 100 and increases steadily, converging with the green line at approximately 0.62 by a budget of 900.
2. **R1-Zero Reward + Budget Prompt (Orange):** Exhibits a flat, high trend. Accuracy remains stable at approximately 0.65 across all thinking budget values.
3. **R1-Zero Reward (Green):** Exhibits a flat, high trend. Accuracy remains stable at approximately 0.62 across all thinking budget values.
4. **MaxLength Reward (Red):** Exhibits a flat, low trend. Accuracy remains stable at approximately 0.35 across all thinking budget values.
### Key Observations
* **Divergent Response Length Behavior:** Only the "MaxDiff Reward" method shows a response length that scales with the thinking budget. The other three methods produce responses of fixed length regardless of the budget allocated.
* **Accuracy Convergence:** The accuracy of the "MaxDiff Reward" method improves significantly with budget, eventually matching the accuracy of the fixed-length "R1-Zero Reward" method at the highest budget levels.
* **Performance Hierarchy:** In terms of accuracy, a clear hierarchy is maintained across all budgets: "R1-Zero Reward + Budget Prompt" (highest) > "R1-Zero Reward" > "MaxDiff Reward" (at low budgets) / "MaxLength Reward" (lowest).
* **MaxLength Reward Trade-off:** The "MaxLength Reward" method consistently produces the shortest responses and achieves the lowest accuracy, indicating a potential trade-off between extreme brevity and performance.
### Interpretation
The data suggests a fundamental difference in how these reward methods operate and respond to increased computational resources (the "thinking budget").
* **MaxDiff Reward** appears to be a **budget-aware, scaling method**. It utilizes the additional budget to generate longer, more detailed responses, which in turn leads to higher accuracy. Its performance is directly tied to the resources provided.
* **R1-Zero Reward** and its variant with a **Budget Prompt** are **budget-agnostic, fixed-output methods**. They produce responses of a predetermined length and quality, irrespective of the available thinking budget. The "Budget Prompt" variant consistently achieves the highest accuracy, suggesting it is the most effective fixed-length strategy among those tested.
* **MaxLength Reward** acts as a **strict length constraint**, capping responses at a very low token count. This severe constraint appears to limit the model's ability to reason or elaborate, resulting in consistently poor accuracy.
The charts demonstrate that for the "MaxDiff Reward" approach, there is a positive correlation between allowed thinking budget, response length, and accuracy. For the other methods, accuracy is decoupled from the thinking budget, as their output length is fixed. This highlights a key design choice in AI system optimization: whether to allow flexible, resource-dependent output or to enforce fixed, predictable output characteristics.