## Line Graphs: Response Lengths and Accuracy Across Experiments
### Overview
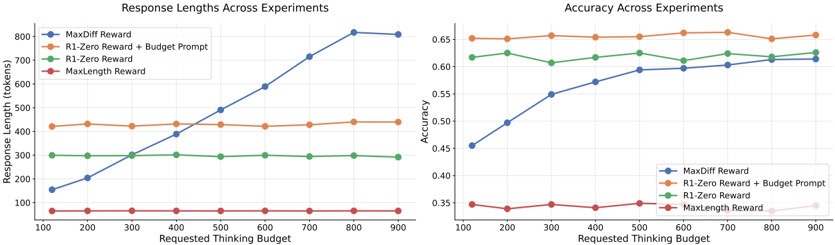
The image contains two line graphs comparing performance metrics (response length and accuracy) across different reward strategies as a function of "Requested Thinking Budget" (x-axis). The graphs use four distinct data series, each represented by a unique color and labeled in the legend.
---
### Components/Axes
#### Left Graph: Response Lengths Across Experiments
- **X-axis**: "Requested Thinking Budget" (range: 100–900, increments of 100)
- **Y-axis**: "Response Length (tokens)" (range: 100–800, increments of 100)
- **Legend**:
- **Blue**: MaxDiff Reward
- **Orange**: R1-Zero Reward + Budget Prompt
- **Green**: R1-Zero Reward
- **Red**: MaxLength Reward
#### Right Graph: Accuracy Across Experiments
- **X-axis**: "Requested Thinking Budget" (same scale as left graph)
- **Y-axis**: "Accuracy" (range: 0.35–0.65, increments of 0.05)
- **Legend**: Same as left graph (blue, orange, green, red)
---
### Detailed Analysis
#### Left Graph: Response Lengths
1. **MaxDiff Reward (Blue)**:
- Starts at ~150 tokens (budget=100) and increases linearly to ~800 tokens (budget=900).
- Slope: ~7.2 tokens per unit budget (calculated from (800-150)/(900-100)).
2. **R1-Zero Reward + Budget Prompt (Orange)**:
- Flat line at ~420–450 tokens across all budgets.
3. **R1-Zero Reward (Green)**:
- Flat line at ~300 tokens across all budgets.
4. **MaxLength Reward (Red)**:
- Flat line at ~50 tokens across all budgets.
#### Right Graph: Accuracy
1. **MaxDiff Reward (Blue)**:
- Starts at ~0.45 (budget=100) and increases to ~0.65 (budget=900).
- Slope: ~0.0022 per unit budget ((0.65-0.45)/(900-100)).
2. **R1-Zero Reward + Budget Prompt (Orange)**:
- Starts at ~0.65, dips slightly to ~0.63 (budget=300), then stabilizes at ~0.65.
3. **R1-Zero Reward (Green)**:
- Starts at ~0.62, peaks at ~0.64 (budget=500), then stabilizes at ~0.63.
4. **MaxLength Reward (Red)**:
- Starts at ~0.35, peaks at ~0.37 (budget=500), then declines to ~0.34.
---
### Key Observations
1. **Response Length**:
- MaxDiff Reward scales linearly with budget, while other strategies show no budget-dependent growth.
- MaxLength Reward produces the shortest responses (~50 tokens) regardless of budget.
2. **Accuracy**:
- MaxDiff Reward improves significantly with budget, achieving ~0.65 accuracy at budget=900.
- R1-Zero Reward + Budget Prompt maintains the highest baseline accuracy (~0.65) but shows no improvement with budget.
- MaxLength Reward underperforms in accuracy, peaking at ~0.37.
---
### Interpretation
1. **MaxDiff Reward**:
- Demonstrates strong scalability: both response length and accuracy improve proportionally with budget. This suggests it effectively balances depth and correctness.
2. **R1-Zero Reward + Budget Prompt**:
- Maintains high accuracy without requiring additional budget, indicating efficiency but limited adaptability to increased computational resources.
3. **MaxLength Reward**:
- Prioritizes brevity over accuracy, producing minimal responses with suboptimal performance. Likely unsuitable for tasks requiring detailed reasoning.
4. **R1-Zero Reward**:
- Balances moderate response length and accuracy but shows no improvement with budget, suggesting diminishing returns.
The data implies that **MaxDiff Reward** is the most effective strategy for tasks requiring scalable, high-quality outputs, while **R1-Zero Reward + Budget Prompt** offers a stable, efficient alternative for fixed-budget scenarios.