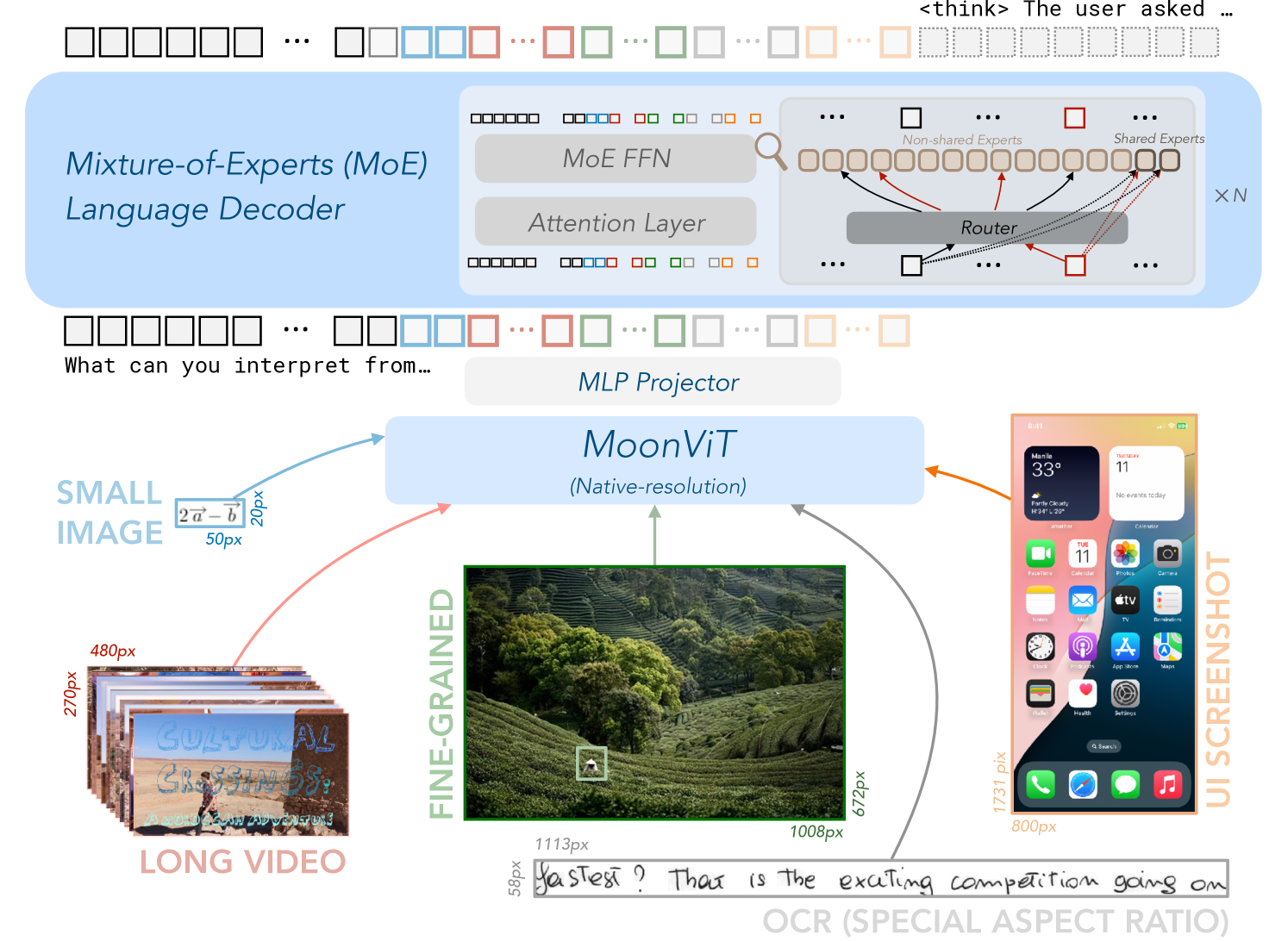
## Diagram: Mixture-of-Experts (MoE) Language Decoder & MoonViT Pipeline
### Overview
This diagram illustrates a pipeline combining a Mixture-of-Experts (MoE) language decoder with a MoonViT (Multi-scale Vision Transformer) model for processing visual data. The pipeline takes long videos or small images as input, processes them through MoonViT, projects the features using an MLP (Multi-Layer Perceptron), and then feeds them into the MoE language decoder. A screenshot of a mobile phone UI is also included, seemingly representing the output or application of the system.
### Components/Axes
The diagram is segmented into several key components:
* **Mixture-of-Experts (MoE) Language Decoder:** Located in the top-left, this section depicts the architecture of the MoE decoder. It includes "MoE FFN" (Feed Forward Network), "Attention Layer", and a "Router" connecting to "Non-shared Experts" and "Shared Experts". The Router has arrows pointing to multiple expert blocks, labeled "X N".
* **MoonViT:** Positioned in the center, this component represents the vision transformer model. It's labeled "(Native-resolution)".
* **MLP Projector:** A rectangular block between MoonViT and the MoE decoder.
* **Input Data:** Two input sources are shown: "LONG VIDEO" (stacked video frames) and "SMALL IMAGE".
* **Fine-Grained:** A section displaying a detailed image of a person.
* **Screenshot:** A UI screenshot of a mobile phone, labeled "UI SCREENSHOT", is on the right.
* **Arrows & Dimensions:** Arrows indicate the data flow, with pixel dimensions labeled along the arrows (e.g., "20px", "50px", "270px", "480px", "59px", "1113px", "100px", "672px", "1731px", "800px").
* **Text:** Several text blocks are present, including "What can you interpret from...", "2a-b", "Text? That is the exciting competition going on", and "OCR (SPECIAL ASPECT RATIO)".
### Detailed Analysis or Content Details
**1. MoE Language Decoder:**
* The MoE decoder consists of an Attention Layer, an MoE FFN, and a Router.
* The Router directs input to both "Non-shared Experts" and "Shared Experts".
* The "X N" notation suggests a variable number of experts (N).
**2. MoonViT:**
* The MoonViT model operates at "Native-resolution".
**3. Input Data Flow:**
* **Long Video:** A stack of video frames (approximately 270px high and 480px wide) is fed into MoonViT via a 50px arrow.
* **Small Image:** A single image (dimensions not explicitly stated, but implied to be smaller than the video frames) is also fed into MoonViT via a 20px arrow.
* **Fine-Grained Image:** A detailed image of a person (approximately 59px high and 1113px wide) is shown, likely representing the output of MoonViT or an intermediate representation.
**4. MLP Projector:**
* The MLP projector connects MoonViT to the MoE decoder.
**5. Screenshot:**
* The screenshot displays a mobile phone UI with various app icons.
* The top of the screen shows "33°" and "11" (likely temperature and time).
* Visible app icons include: Calendar, Safari, App Store, Camera, Photos, Clock, Music, and others.
* The screenshot is approximately 1731px high and 800px wide.
**6. Text Blocks:**
* "What can you interpret from..." - A prompt or question.
* "2a-b" - A mathematical expression or label.
* "Text? That is the exciting competition going on" - A statement about the current research landscape.
* "OCR (SPECIAL ASPECT RATIO)" - Indicates Optical Character Recognition is being used, potentially with a focus on handling varying aspect ratios.
### Key Observations
* The diagram highlights a multi-modal approach, combining visual processing (MoonViT) with language modeling (MoE decoder).
* The use of MoE suggests a focus on scalability and efficiency in the language decoder.
* The inclusion of pixel dimensions indicates a concern for computational resources and model size.
* The screenshot suggests the system is intended for use on mobile devices.
* The "OCR (SPECIAL ASPECT RATIO)" label suggests the system may be designed to process text from images with varying aspect ratios.
### Interpretation
The diagram depicts a system designed to understand and generate language based on visual input. The MoonViT model extracts features from images or videos, which are then projected and fed into the MoE language decoder. The MoE decoder likely generates text descriptions or answers questions about the visual content. The system's architecture suggests a focus on handling complex visual scenes and generating coherent language outputs. The inclusion of the mobile phone screenshot implies a potential application in areas such as image captioning, visual question answering, or assistive technology for mobile devices. The mention of OCR and special aspect ratios suggests the system is robust to variations in text presentation within images. The overall pipeline represents a sophisticated approach to multi-modal learning, leveraging the strengths of both vision transformers and mixture-of-experts language models. The "What can you interpret from..." prompt suggests the diagram is part of a presentation or research paper exploring the capabilities of this system.