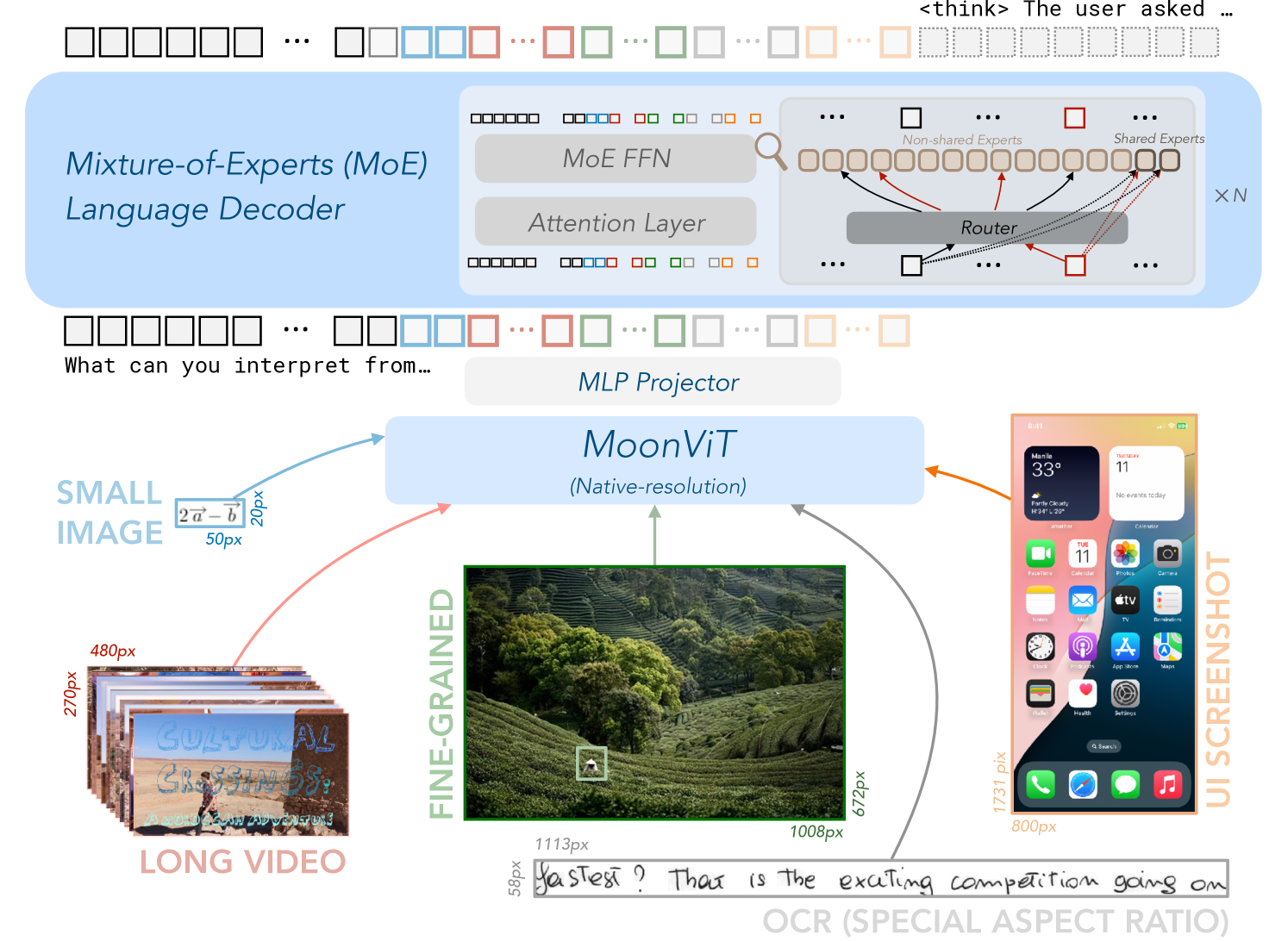
## Diagram: Multimodal Processing Architecture with Mixture-of-Experts and MoonViT
### Overview
The diagram illustrates a technical architecture for multimodal processing, combining text and image analysis. It features a Mixture-of-Experts (MoE) Language Decoder, an MLP Projector, and MoonViT (a vision transformer) with native-resolution processing. The system integrates long video, fine-grained images, and UI screenshots, with OCR text extraction as output.
### Components/Axes
1. **Top Section (MoE Language Decoder)**:
- **MoE FFN**: Feed-forward neural network with mixture-of-experts.
- **Attention Layer**: Standard transformer attention mechanism.
- **Router**: Distributes inputs to shared/non-shared experts.
- **Experts**: Labeled as "Shared Experts" and "Non-shared Experts" with color-coded connections (red, blue, green, orange).
2. **Middle Section (MLP Projector)**:
- Connects MoE Decoder to MoonViT.
3. **Bottom Section (MoonViT)**:
- **Input Sources**:
- **Long Video**: 270px × 480px (stacked frames).
- **Fine-grained Image**: 1008px × 672px (detailed landscape).
- **UI Screenshot**: 800px × 1731px (mobile interface).
- **Output**: OCR text ("Yas test? That is the exciting competition going on").
4. **Textual Elements**:
- **Input Prompt**: "What can you interpret from..."
- **Output Text**: OCR-extracted text from MoonViT.
### Detailed Analysis
- **MoE Decoder**:
- The Router directs inputs to experts based on query complexity (e.g., red arrows for high-priority tasks).
- Non-shared experts (orange) handle specialized tasks, while shared experts (blue/green) manage common operations.
- **MoonViT**:
- Processes inputs at varying resolutions (20px, 50px, 480px, 1113px, 1008px, 800px).
- Outputs OCR text, suggesting text extraction from images (e.g., "CULTURAL CROSSINGS" from the long video).
- **UI Screenshot**:
- Contains app icons (Calendar, Photos, Camera) and system info (weather: 33°C in Manila).
### Key Observations
1. **Multimodal Integration**: Combines text decoding (MoE) with vision processing (MoonViT).
2. **Resolution Handling**: MoonViT adapts to diverse image sizes (e.g., 20px for small images, 1008px for fine-grained details).
3. **OCR Capability**: Explicitly extracts text from images (e.g., "CULTURAL CROSSINGS" and "Yas test?").
### Interpretation
- **Efficiency**: MoE architecture reduces computational costs by activating only relevant experts.
- **Adaptability**: MoonViT’s native-resolution processing handles diverse visual inputs (e.g., UI elements, natural scenes).
- **Text-Image Link**: OCR output demonstrates the system’s ability to bridge visual and textual data, useful for tasks like document analysis or UI automation.
- **Potential Use Cases**: Multimodal chatbots, video captioning, or UI element recognition.
## Notes
- No numerical data or trends present; focus is on architectural components and workflow.
- All text is in English; no foreign languages detected.
- Spatial grounding confirms connections via color-coded arrows (e.g., red for high-priority routing).