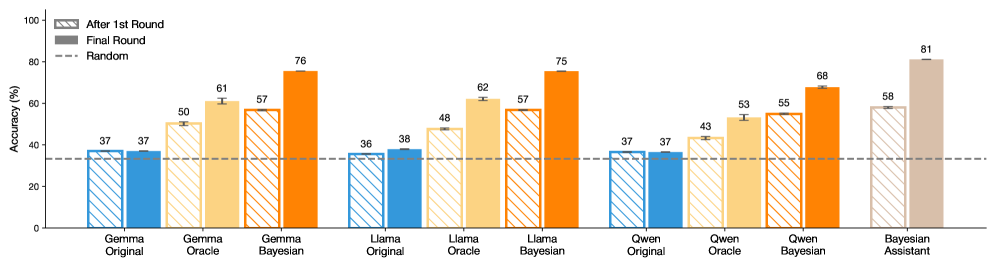
## Bar Chart: Model Accuracy Comparison
### Overview
The image is a bar chart comparing the accuracy of different language models (Gemma, Llama, Qwen, and Bayesian Assistant) under various conditions: "Original", "Oracle", and "Bayesian". The chart displays accuracy percentages for each model after the "1st Round" (striped bars) and in the "Final Round" (solid bars). A dashed horizontal line indicates the "Random" accuracy level.
### Components/Axes
* **Y-axis:** "Accuracy (%)", ranging from 0 to 100. Increments of 20 are marked (0, 20, 40, 60, 80, 100).
* **X-axis:** Categorical axis representing different language models and their variations:
* Gemma (Original, Oracle, Bayesian)
* Llama (Original, Oracle, Bayesian)
* Qwen (Original, Oracle, Bayesian)
* Bayesian Assistant
* **Legend:** Located at the top-left corner:
* Striped bars: "After 1st Round"
* Solid bars: "Final Round"
* Dashed line: "Random"
### Detailed Analysis
**Gemma:**
* **Original:** Accuracy is 37% after the 1st round and 37% in the final round.
* **Oracle:** Accuracy is 50% after the 1st round and 61% in the final round.
* **Bayesian:** Accuracy is 57% after the 1st round and 76% in the final round.
**Llama:**
* **Original:** Accuracy is 36% after the 1st round and 38% in the final round.
* **Oracle:** Accuracy is 48% after the 1st round and 62% in the final round.
* **Bayesian:** Accuracy is 57% after the 1st round and 75% in the final round.
**Qwen:**
* **Original:** Accuracy is 37% after the 1st round and 37% in the final round.
* **Oracle:** Accuracy is 43% after the 1st round and 53% in the final round.
* **Bayesian:** Accuracy is 55% after the 1st round and 68% in the final round.
**Bayesian Assistant:**
* Accuracy is 58% after the 1st round and 81% in the final round.
**Random Accuracy:**
* The dashed line indicates a random accuracy level of approximately 33%.
### Key Observations
* All models generally show an increase in accuracy from the "1st Round" to the "Final Round," except for Gemma and Qwen "Original" which remain constant.
* The "Bayesian" versions of Gemma, Llama, and Qwen consistently outperform their "Original" and "Oracle" counterparts.
* The "Bayesian Assistant" achieves the highest final round accuracy (81%) among all models.
* The "Original" versions of Gemma, Llama, and Qwen have very low accuracy, close to the "Random" level.
### Interpretation
The chart demonstrates the impact of different training approaches ("Oracle" and "Bayesian") on the accuracy of language models. The "Bayesian" approach appears to significantly improve model performance compared to the "Original" versions. The "Bayesian Assistant" model stands out as the most accurate among those tested. The "Original" models perform poorly, suggesting that they may require further training or optimization. The "Oracle" models show improvement over the "Original" models, but not as much as the "Bayesian" models.