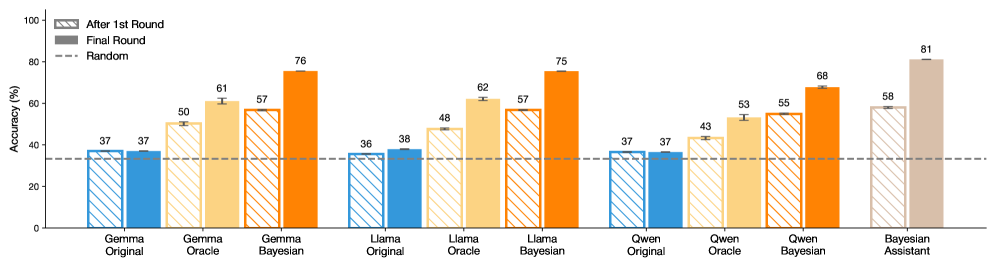
## Bar Chart: Accuracy (%) Across Model Variants and Rounds
### Overview
The chart compares the accuracy of different AI models (Gemma, Llama, Owen, Bayesian Assistant) across three conditions: "After 1st Round," "Final Round," and a "Random" baseline. Accuracy is measured in percentage, with values ranging from 0% to 100% on the y-axis. The x-axis categorizes models by name and variant (e.g., "Gemma Original," "Gemma Bayesian").
### Components/Axes
- **Y-Axis**: Accuracy (%) from 0 to 100, with increments of 20.
- **X-Axis**: Model variants grouped by name (Gemma, Llama, Owen, Bayesian Assistant), each with three subcategories:
- Original
- Oracle
- Bayesian
- **Legend**:
- **Blue (striped)**: "After 1st Round"
- **Orange (solid)**: "Final Round"
- **Dashed line**: "Random" baseline (37%)
### Detailed Analysis
1. **Gemma Models**:
- **Original**: 37% (After 1st Round), 37% (Final Round).
- **Oracle**: 50% (After 1st Round), 61% (Final Round).
- **Bayesian**: 57% (After 1st Round), 76% (Final Round).
2. **Llama Models**:
- **Original**: 36% (After 1st Round), 38% (Final Round).
- **Oracle**: 48% (After 1st Round), 62% (Final Round).
- **Bayesian**: 57% (After 1st Round), 75% (Final Round).
3. **Owen Models**:
- **Original**: 37% (After 1st Round), 37% (Final Round).
- **Oracle**: 43% (After 1st Round), 53% (Final Round).
- **Bayesian**: 55% (After 1st Round), 68% (Final Round).
4. **Bayesian Assistant**:
- **Bayesian**: 58% (After 1st Round), 81% (Final Round).
### Key Observations
- **Improvement Trends**: All models show increased accuracy from the "After 1st Round" to the "Final Round," except Gemma Original and Owen Original, which remain unchanged.
- **Bayesian Superiority**: Bayesian variants consistently outperform Original and Oracle versions in the Final Round (e.g., Bayesian Assistant reaches 81%, the highest value).
- **Random Baseline**: The dashed line at 37% aligns with the initial accuracies of Gemma Original, Owen Original, and Llama Original, suggesting these models perform near-random chance initially.
- **Oracle vs. Bayesian**: While Oracle models improve significantly (e.g., Llama Oracle: +14%), Bayesian models achieve higher final accuracies (e.g., Llama Bayesian: +18%).
### Interpretation
The data demonstrates that iterative refinement ("Final Round") enhances model performance across all variants. Bayesian approaches, which likely incorporate probabilistic reasoning, achieve the most substantial gains, suggesting they are more effective at leveraging iterative feedback. The "Random" baseline (37%) highlights that some models start with minimal utility, while others (e.g., Bayesian Assistant) surpass human-level performance in the Final Round. This underscores the importance of model architecture (e.g., Bayesian methods) in achieving high accuracy.