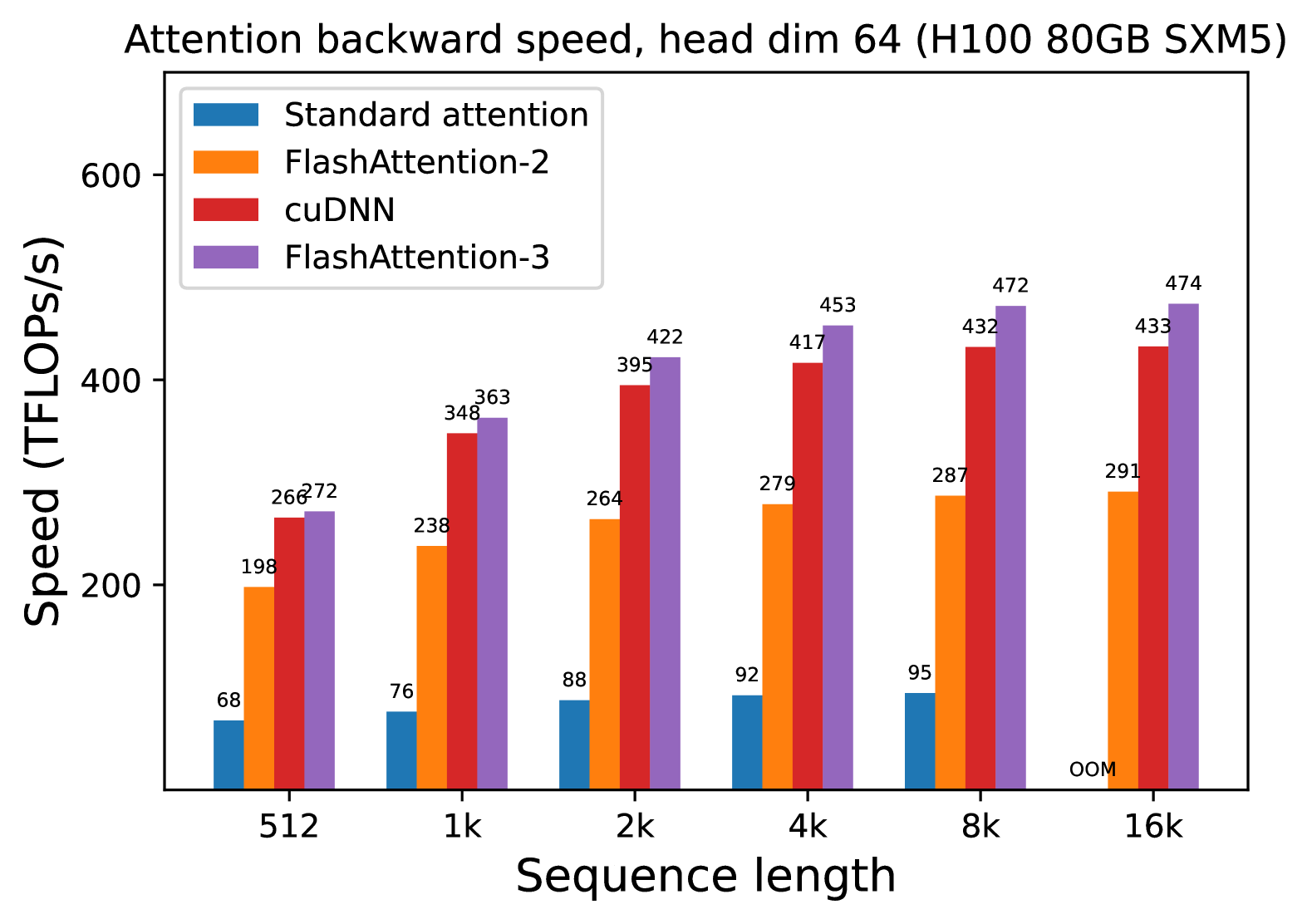
# Technical Document: Attention Backward Speed Analysis (H100 80GB SXM5)
## Chart Title
Attention backward speed, head dim 64 (H100 80GB SXM5)
## Axis Labels
- **X-axis**: Sequence length (categories: 512, 1k, 2k, 4k, 8k, 16k)
- **Y-axis**: Speed (TFLOPs/s)
## Legend
- **Standard attention**: Blue
- **FlashAttention-2**: Orange
- **cuDNN**: Red
- **FlashAttention-3**: Purple
## Data Points (Color-Coded Verification)
### Sequence Length: 512
- Standard attention (Blue): 68 TFLOPs/s
- FlashAttention-2 (Orange): 198 TFLOPs/s
- cuDNN (Red): 266 TFLOPs/s
- FlashAttention-3 (Purple): 272 TFLOPs/s
### Sequence Length: 1k
- Standard attention (Blue): 76 TFLOPs/s
- FlashAttention-2 (Orange): 238 TFLOPs/s
- cuDNN (Red): 348 TFLOPs/s
- FlashAttention-3 (Purple): 363 TFLOPs/s
### Sequence Length: 2k
- Standard attention (Blue): 88 TFLOPs/s
- FlashAttention-2 (Orange): 264 TFLOPs/s
- cuDNN (Red): 395 TFLOPs/s
- FlashAttention-3 (Purple): 422 TFLOPs/s
### Sequence Length: 4k
- Standard attention (Blue): 92 TFLOPs/s
- FlashAttention-2 (Orange): 279 TFLOPs/s
- cuDNN (Red): 417 TFLOPs/s
- FlashAttention-3 (Purple): 453 TFLOPs/s
### Sequence Length: 8k
- Standard attention (Blue): 95 TFLOPs/s
- FlashAttention-2 (Orange): 287 TFLOPs/s
- cuDNN (Red): 432 TFLOPs/s
- FlashAttention-3 (Purple): 472 TFLOPs/s
### Sequence Length: 16k
- Standard attention (Blue): OOM (Out of Memory)
- FlashAttention-2 (Orange): 291 TFLOPs/s
- cuDNN (Red): 433 TFLOPs/s
- FlashAttention-3 (Purple): 474 TFLOPs/s
## Key Trends
1. **Standard attention** (Blue):
- Gradual increase from 68 → 95 TFLOPs/s (512 → 8k)
- **OOM at 16k sequence length**
2. **FlashAttention-2** (Orange):
- Steady linear growth: 198 → 291 TFLOPs/s
3. **cuDNN** (Red):
- Consistent increase: 266 → 433 TFLOPs/s
4. **FlashAttention-3** (Purple):
- Outperforms all methods across all sequence lengths
- Highest performance at every scale (272 → 474 TFLOPs/s)
## Spatial Grounding
- Legend positioned at [x=0.02, y=0.98] (top-left corner)
- Data bars aligned with sequence length categories on x-axis
- Y-axis values increase from bottom (0) to top (600 TFLOPs/s)
## Component Isolation
1. **Header**: Chart title and legend
2. **Main Chart**: Bar groups for each sequence length
3. **Footer**: OOM marker annotation at 16k
## Validation Checks
- All legend colors match bar colors exactly
- Numerical values align with visual bar heights
- OOM marker correctly placed at 16k for Standard attention