\n
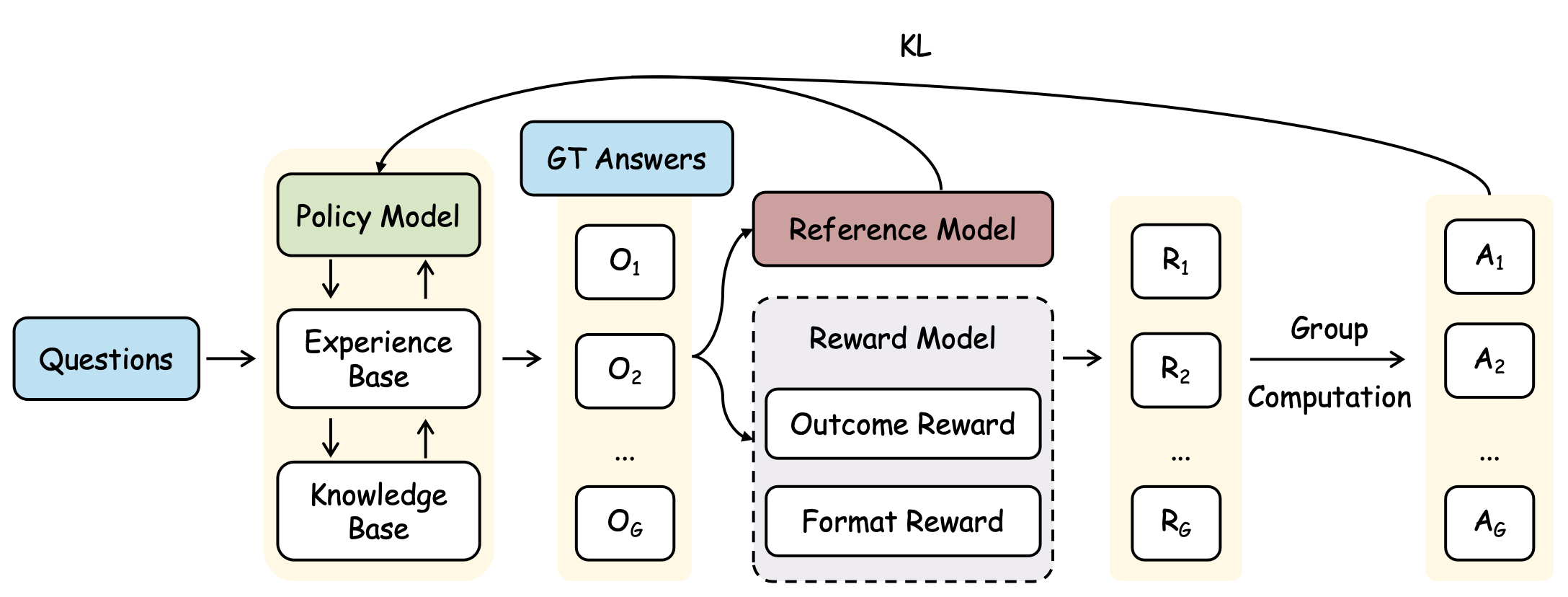
## Diagram: Reinforcement Learning from Human Feedback (RLHF) System
### Overview
This diagram illustrates a system for Reinforcement Learning from Human Feedback (RLHF). It depicts the flow of information through a policy model, a reference model, a reward model, and a group computation stage. The system takes questions as input and generates answers, refining the policy model based on feedback.
### Components/Axes
The diagram consists of the following components:
* **Questions:** Input to the system.
* **Policy Model:** Generates outputs based on questions and experience.
* **Experience Base:** Stores experiences used by the Policy Model.
* **Knowledge Base:** Stores knowledge used by the Policy Model.
* **GT Answers:** Ground Truth Answers, used for comparison.
* **Reference Model:** Evaluates the outputs of the Policy Model.
* **Reward Model:** Provides rewards based on outcome and format.
* **Outcome Reward:** Reward based on the result.
* **Format Reward:** Reward based on the format of the result.
* **O<sub>1</sub>…O<sub>6</sub>:** Outputs from the Policy Model.
* **R<sub>1</sub>…R<sub>6</sub>:** Rewards from the Reward Model.
* **A<sub>1</sub>…A<sub>6</sub>:** Answers from the Group Computation.
* **Group Computation:** Aggregates rewards to refine the Policy Model.
* **KL:** Kullback-Leibler divergence, used to constrain the Policy Model.
Arrows indicate the direction of information flow.
### Detailed Analysis / Content Details
The diagram shows a cyclical process:
1. **Questions** are fed into the **Policy Model**.
2. The **Policy Model** utilizes the **Experience Base** and **Knowledge Base** to generate outputs **O<sub>1</sub>** through **O<sub>6</sub>**.
3. These outputs are compared to **GT Answers** and evaluated by the **Reference Model**.
4. The **Reference Model** feeds into the **Reward Model**, which calculates **Outcome Reward** and **Format Reward**.
5. The **Reward Model** outputs rewards **R<sub>1</sub>** through **R<sub>6</sub>**.
6. **Group Computation** aggregates these rewards.
7. The aggregated rewards are used to refine the **Policy Model**, constrained by the **KL** divergence.
8. The **Group Computation** outputs answers **A<sub>1</sub>** through **A<sub>6</sub>**.
The diagram does not provide specific numerical values or quantitative data. It is a conceptual representation of the system's architecture.
### Key Observations
The diagram highlights the iterative nature of RLHF. The Policy Model is continuously refined based on feedback from the Reward Model, which in turn is informed by the Reference Model and Ground Truth Answers. The KL divergence suggests a mechanism to prevent the Policy Model from deviating too far from its initial state. The use of both Outcome and Format Rewards indicates a focus on both the correctness and presentation of the generated answers.
### Interpretation
This diagram represents a sophisticated system for training a language model to generate high-quality responses. The RLHF approach allows the model to learn from human preferences, leading to more aligned and useful outputs. The separation of Outcome and Format Rewards allows for fine-grained control over the generation process. The inclusion of a Reference Model and Ground Truth Answers provides a benchmark for evaluating the model's performance. The KL divergence constraint is crucial for maintaining stability and preventing catastrophic forgetting. The diagram suggests a complex interplay between different components, all working together to optimize the Policy Model's performance. The system is designed to learn from experience and adapt to changing requirements, making it a powerful tool for building intelligent agents.