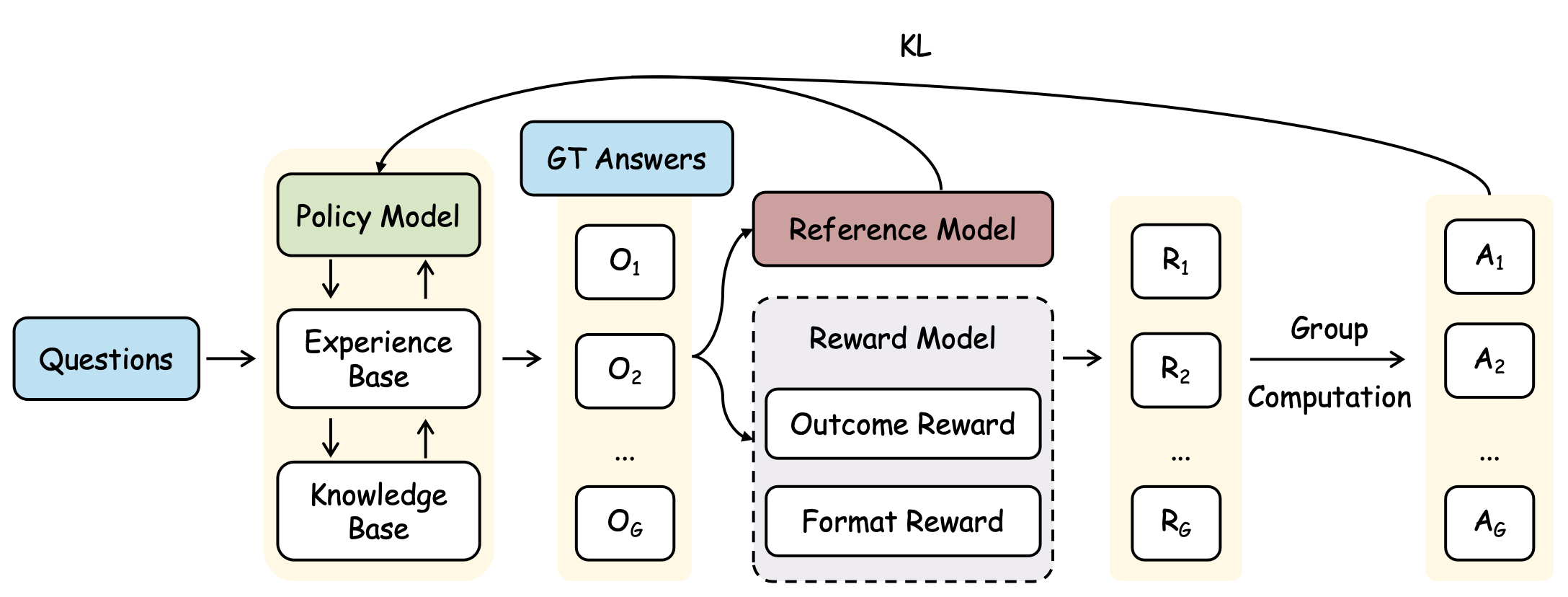
## Flowchart: Reinforcement Learning System Architecture
### Overview
The diagram illustrates a reinforcement learning (RL) system architecture with interconnected components. It shows the flow of data from input questions to policy model outputs, incorporating feedback loops and reward-based optimization. Key elements include policy modeling, experience/knowledge bases, ground truth (GT) answers, reference modeling, and group computation.
### Components/Axes
- **Input**: "Questions" (blue box, left side)
- **Core Components**:
- **Policy Model** (green box, central)
- **Experience Base** (white box, connected to Policy Model)
- **Knowledge Base** (white box, connected to Policy Model)
- **GT Answers** (blue box, top-center)
- **Reference Model** (brown box, central-right)
- **Reward Model** (gray dashed box, right-center)
- **Group Computation** (labeled, right side)
- **Output**: "A₁" to "A_G" (action outputs, rightmost column)
- **Legend**: "KL" (top-right, likely denotes key labels or components)
### Detailed Analysis
1. **Flow Path**:
- **Left Path**:
- Questions → Policy Model → Experience Base ↔ Knowledge Base
- Experience Base outputs (O₁ to O_G) feed back into Policy Model
- **Right Path**:
- GT Answers → Reference Model → Reward Model (Outcome Reward + Format Reward)
- Reward Model outputs (R₁ to R_G) → Group Computation → A₁ to A_G
- A₁ to A_G loop back to Reference Model
2. **Color Coding**:
- Policy Model: Green
- GT Answers: Blue
- Reference Model: Brown
- Reward Model: Gray (dashed)
- Arrows: Black
3. **Structural Notes**:
- Dashed lines indicate optional or evaluative components (Reward Model)
- Double-sided arrows (↔) suggest bidirectional data exchange (Experience ↔ Knowledge Base)
- Group Computation acts as an aggregator for final action outputs
### Key Observations
- **Feedback Loops**:
- Experience/Knowledge Base ↔ Policy Model
- Actions (A₁-A_G) → Reference Model (creates closed-loop optimization)
- **Reward Structure**:
- Two reward types (Outcome + Format) suggest multi-criteria optimization
- Reward Model outputs (R₁-R_G) are grouped before final action computation
- **Modular Design**:
- Clear separation between policy generation (left) and evaluation/optimization (right)
### Interpretation
This architecture represents a hybrid RL system combining:
1. **Experience-driven learning** (Experience Base ↔ Policy Model)
2. **Knowledge integration** (Knowledge Base as external memory)
3. **Ground truth supervision** (GT Answers → Reference Model)
4. **Multi-objective reward shaping** (Outcome + Format rewards)
5. **Ensemble action selection** (Group Computation aggregating R₁-R_G)
The system likely implements Proximal Policy Optimization (PPO) or similar RL framework with:
- Experience replay (Experience Base)
- Knowledge distillation (Knowledge Base)
- Multi-task reward shaping
- Group-level action selection for robustness
Notable design choices:
- The Reference Model acts as a "teacher" providing GT answers and reward signals
- The Reward Model's dashed outline suggests it may be a separate training component
- Group Computation implies ensemble methods for action selection