# Technical Document Extraction: Speedup on Different Model Sizes
## 1. Document Overview
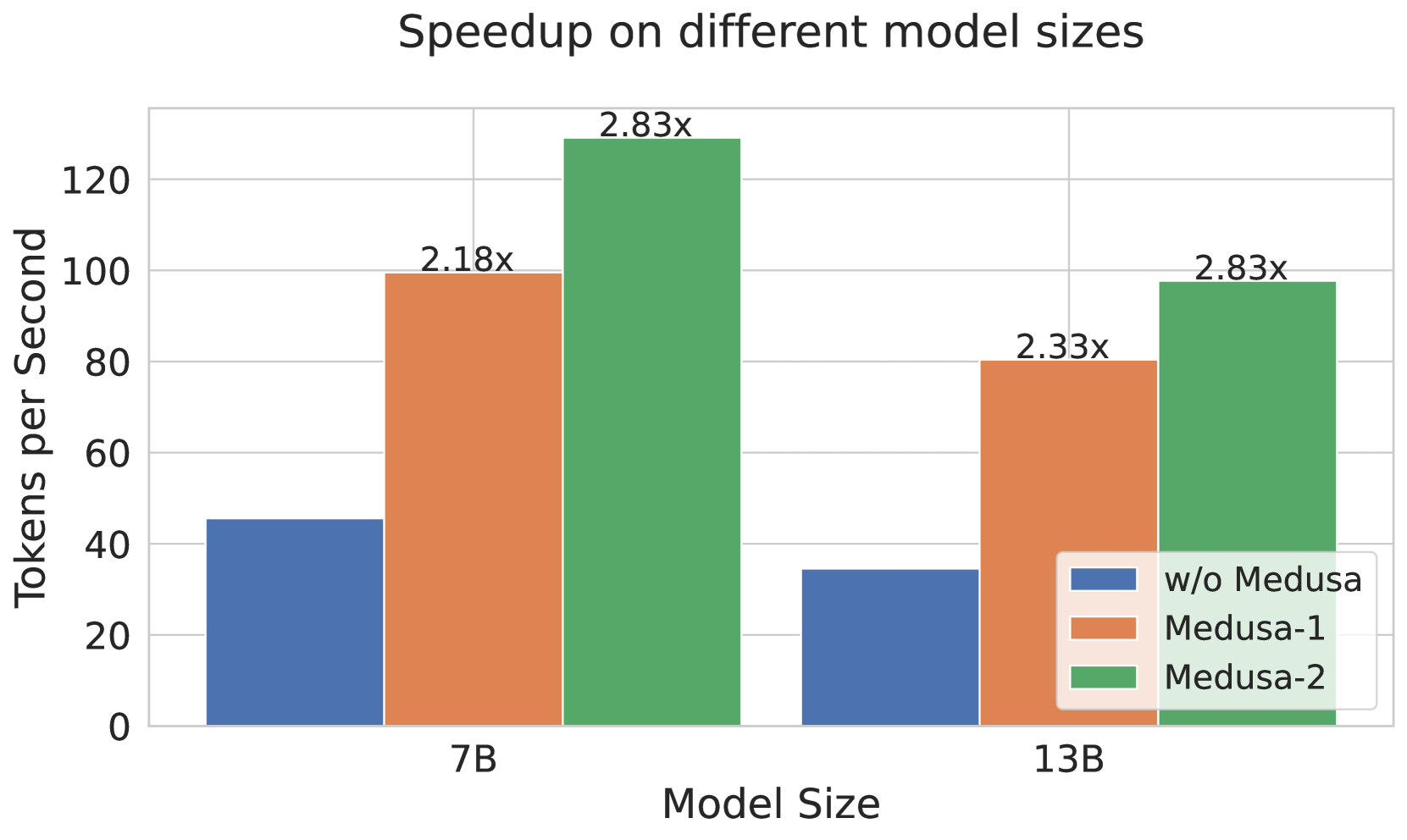
This image is a grouped bar chart illustrating the performance improvements (speedup) achieved by different versions of the "Medusa" system across two Large Language Model (LLM) sizes. The performance is measured in throughput (Tokens per Second).
## 2. Component Isolation
### Header
* **Title:** Speedup on different model sizes
### Main Chart Area
* **Y-Axis Label:** Tokens per Second
* **Y-Axis Markers:** 0, 20, 40, 60, 80, 100, 120
* **X-Axis Label:** Model Size
* **X-Axis Categories:** 7B, 13B
* **Grid:** Horizontal grid lines corresponding to the Y-axis markers.
### Legend
* **Blue Square:** w/o Medusa (Baseline)
* **Orange Square:** Medusa-1
* **Green Square:** Medusa-2
## 3. Data Extraction and Trend Analysis
### Trend Verification
1. **Baseline (w/o Medusa):** As model size increases from 7B to 13B, the throughput decreases (the blue bar is shorter for 13B).
2. **Medusa-1:** Shows a significant upward shift from the baseline in both categories.
3. **Medusa-2:** Shows the highest throughput in both categories, consistently outperforming Medusa-1 and the baseline.
4. **Relative Speedup:** The speedup factor (annotated above the bars) increases as the model size increases for Medusa-1 (2.18x to 2.33x), while it remains constant for Medusa-2 (2.83x).
### Data Table (Reconstructed)
| Model Size | Configuration | Tokens per Second (Approx.) | Speedup Factor (Annotated) |
| :--- | :--- | :--- | :--- |
| **7B** | w/o Medusa (Blue) | ~45 | - |
| **7B** | Medusa-1 (Orange) | ~98 | 2.18x |
| **7B** | Medusa-2 (Green) | ~128 | 2.83x |
| **13B** | w/o Medusa (Blue) | ~35 | - |
| **13B** | Medusa-1 (Orange) | ~80 | 2.33x |
| **13B** | Medusa-2 (Green) | ~98 | 2.83x |
## 4. Detailed Observations
* **Performance Scaling:** While absolute throughput (Tokens per Second) drops for all configurations when moving from a 7B to a 13B model, the efficiency gains provided by Medusa become more pronounced or stay stable.
* **Medusa-2 Efficiency:** Medusa-2 on a 13B model (~98 tokens/sec) achieves roughly the same performance as Medusa-1 on a 7B model (~98 tokens/sec), effectively allowing a larger model to run at the speed of a smaller optimized model.
* **Maximum Throughput:** The peak performance recorded is for the 7B model using Medusa-2, reaching approximately 128 tokens per second.