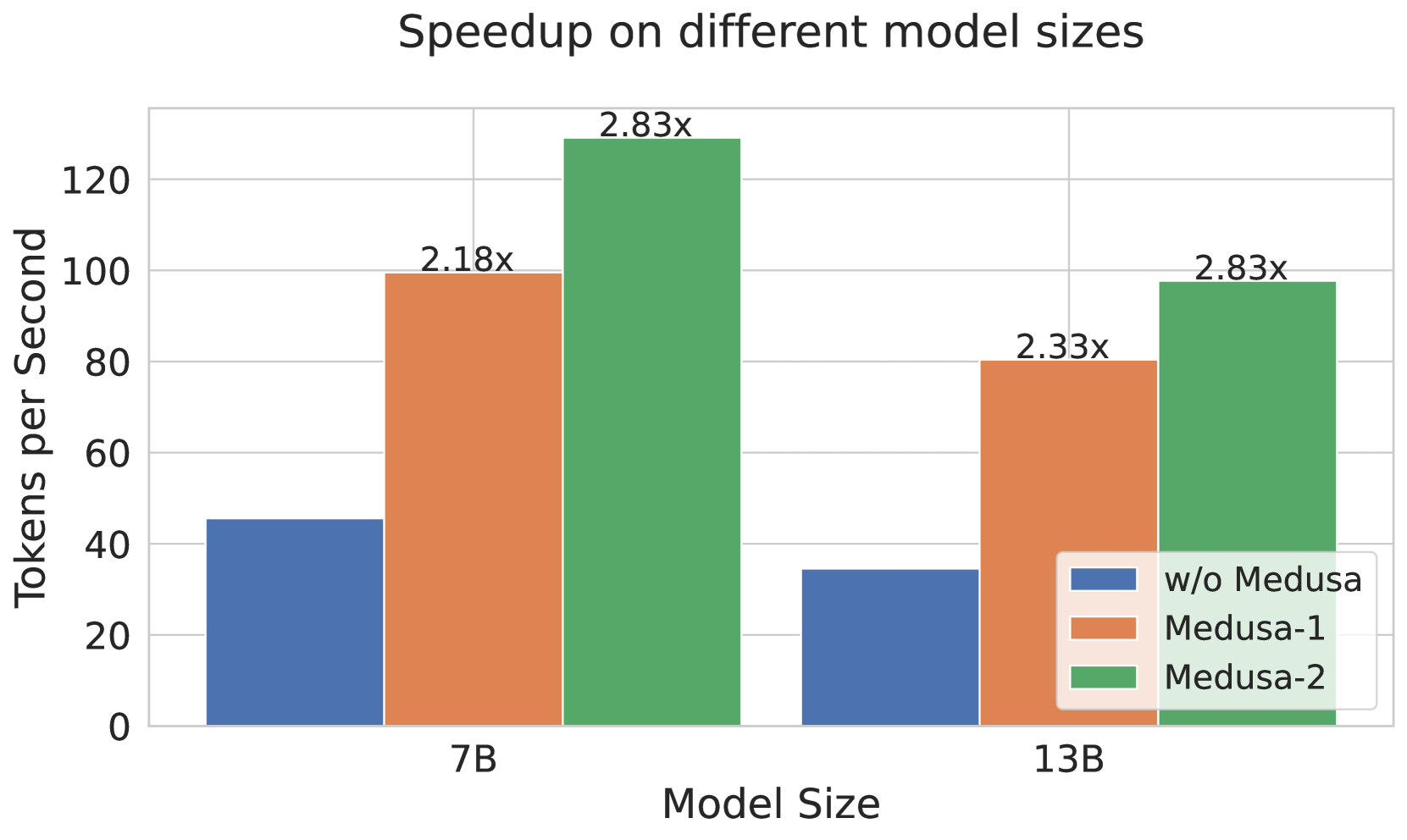
# Technical Document Extraction: Speedup on Different Model Sizes
## Chart Overview
- **Title**: Speedup on different model sizes
- **Type**: Bar chart
- **Purpose**: Compare token processing speed (tokens per second) across model sizes with/without Medusa optimizations
## Axes
- **X-axis (Model Size)**:
- Categories: `7B`, `13B`
- Label: "Model Size"
- **Y-axis (Tokens per Second)**:
- Range: 0–140
- Label: "Tokens per Second"
## Legend
- **Color-Coded Models**:
- `Blue`: w/o Medusa
- `Orange`: Medusa-1
- `Green`: Medusa-2
## Data Points
### Model Size: 7B
- **w/o Medusa** (Blue):
- Tokens per Second: ~45
- Speedup: N/A (baseline)
- **Medusa-1** (Orange):
- Tokens per Second: ~100
- Speedup: `2.18x` (vs. w/o Medusa)
- **Medusa-2** (Green):
- Tokens per Second: ~130
- Speedup: `2.83x` (vs. w/o Medusa)
### Model Size: 13B
- **w/o Medusa** (Blue):
- Tokens per Second: ~35
- Speedup: N/A (baseline)
- **Medusa-1** (Orange):
- Tokens per Second: ~80
- Speedup: `2.33x` (vs. w/o Medusa)
- **Medusa-2** (Green):
- Tokens per Second: ~100
- Speedup: `2.83x` (vs. w/o Medusa)
## Key Observations
1. **Speedup Consistency**:
- Medusa-2 achieves `2.83x` speedup across both 7B and 13B models.
- Medusa-1 shows diminishing returns at larger model sizes (`2.18x` for 7B vs. `2.33x` for 13B).
2. **Performance Scaling**:
- Larger models (13B) process fewer tokens per second than smaller models (7B) in baseline configurations.
- Medusa optimizations improve efficiency more significantly for smaller models.
## Structural Notes
- Bars are grouped by model size, with each group containing three bars (w/o Medusa, Medusa-1, Medusa-2).
- Speedup multipliers are explicitly labeled on top of each colored bar.
- No gridlines or error bars are present in the chart.