\n
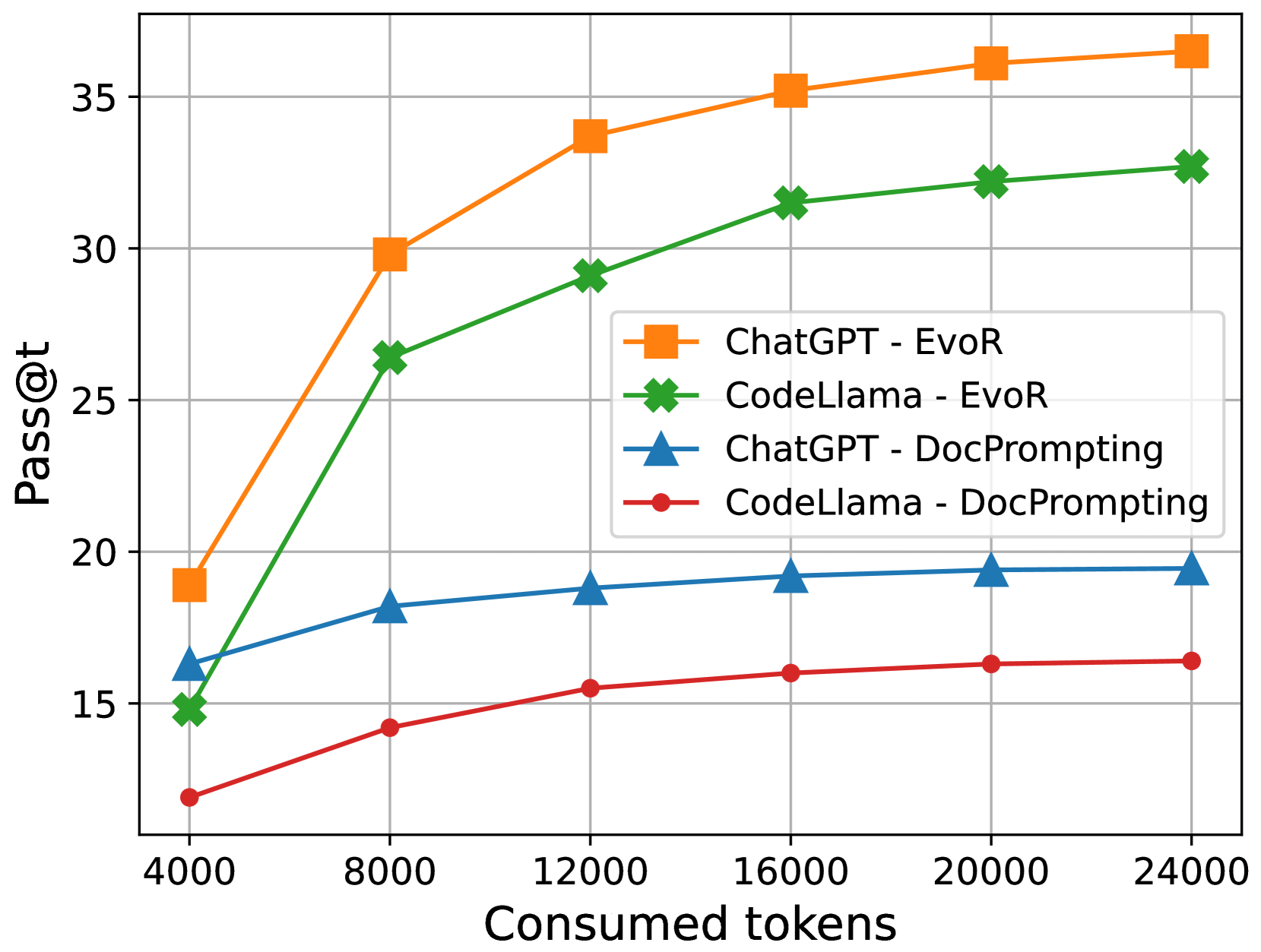
## Line Chart: Performance Comparison of Language Models
### Overview
This line chart compares the performance of two language models, ChatGPT and CodeLlama, under two different prompting strategies: EvoR and DocPrompting. The performance metric is "Pass@t", plotted against the number of "Consumed tokens". The chart visually demonstrates how the performance of each model changes as the number of tokens consumed increases.
### Components/Axes
* **X-axis:** "Consumed tokens" - ranging from approximately 4000 to 24000.
* **Y-axis:** "Pass@t" - ranging from approximately 15 to 35.
* **Data Series:**
* ChatGPT - EvoR (Orange)
* CodeLlama - EvoR (Green)
* ChatGPT - DocPrompting (Blue)
* CodeLlama - DocPrompting (Red)
* **Legend:** Located in the top-right corner of the chart, clearly labeling each data series with its corresponding color.
### Detailed Analysis
Here's a breakdown of each data series, with approximate values extracted from the chart:
* **ChatGPT - EvoR (Orange):** This line slopes sharply upward.
* At 4000 tokens: approximately 19 Pass@t.
* At 8000 tokens: approximately 30 Pass@t.
* At 12000 tokens: approximately 32 Pass@t.
* At 16000 tokens: approximately 34 Pass@t.
* At 20000 tokens: approximately 35 Pass@t.
* At 24000 tokens: approximately 35 Pass@t.
* **CodeLlama - EvoR (Green):** This line also slopes upward, but less steeply than ChatGPT - EvoR.
* At 4000 tokens: approximately 15 Pass@t.
* At 8000 tokens: approximately 26 Pass@t.
* At 12000 tokens: approximately 29 Pass@t.
* At 16000 tokens: approximately 31 Pass@t.
* At 20000 tokens: approximately 32 Pass@t.
* At 24000 tokens: approximately 33 Pass@t.
* **ChatGPT - DocPrompting (Blue):** This line is relatively flat, showing minimal improvement with increasing tokens.
* At 4000 tokens: approximately 15 Pass@t.
* At 8000 tokens: approximately 18 Pass@t.
* At 12000 tokens: approximately 19 Pass@t.
* At 16000 tokens: approximately 20 Pass@t.
* At 20000 tokens: approximately 20 Pass@t.
* At 24000 tokens: approximately 20 Pass@t.
* **CodeLlama - DocPrompting (Red):** This line shows a slight upward trend, but remains the lowest performing series.
* At 4000 tokens: approximately 12 Pass@t.
* At 8000 tokens: approximately 14 Pass@t.
* At 12000 tokens: approximately 15 Pass@t.
* At 16000 tokens: approximately 15 Pass@t.
* At 20000 tokens: approximately 16 Pass@t.
* At 24000 tokens: approximately 16 Pass@t.
### Key Observations
* ChatGPT with EvoR prompting consistently outperforms all other configurations.
* The EvoR prompting strategy yields significantly better results than DocPrompting for both models.
* CodeLlama generally performs lower than ChatGPT across all token ranges and prompting strategies.
* The performance gains from increasing tokens diminish for ChatGPT - EvoR after approximately 16000 tokens.
* The performance of ChatGPT - DocPrompting and CodeLlama - DocPrompting plateaus quickly, indicating limited benefit from increased token consumption.
### Interpretation
The data suggests that the EvoR prompting strategy is far more effective at eliciting desired performance from both ChatGPT and CodeLlama than the DocPrompting strategy. ChatGPT, when combined with EvoR, demonstrates a strong positive correlation between consumed tokens and performance, up to a certain point. This implies that providing more context (through tokens) to ChatGPT with EvoR leads to improved results, but the returns diminish as the token count increases.
CodeLlama, while showing improvement with EvoR and increased tokens, consistently lags behind ChatGPT. This could indicate inherent differences in the models' architectures or training data. The flat performance of both models with DocPrompting suggests that this strategy is not well-suited for the task being evaluated, or that the models require a different approach to leverage the provided context effectively.
The plateauing of ChatGPT-EvoR suggests a point of diminishing returns, where further token consumption does not translate into significant performance gains. This could be due to the model reaching its capacity to effectively process and utilize the additional information. Further investigation would be needed to determine the optimal token count for maximizing performance with EvoR prompting.