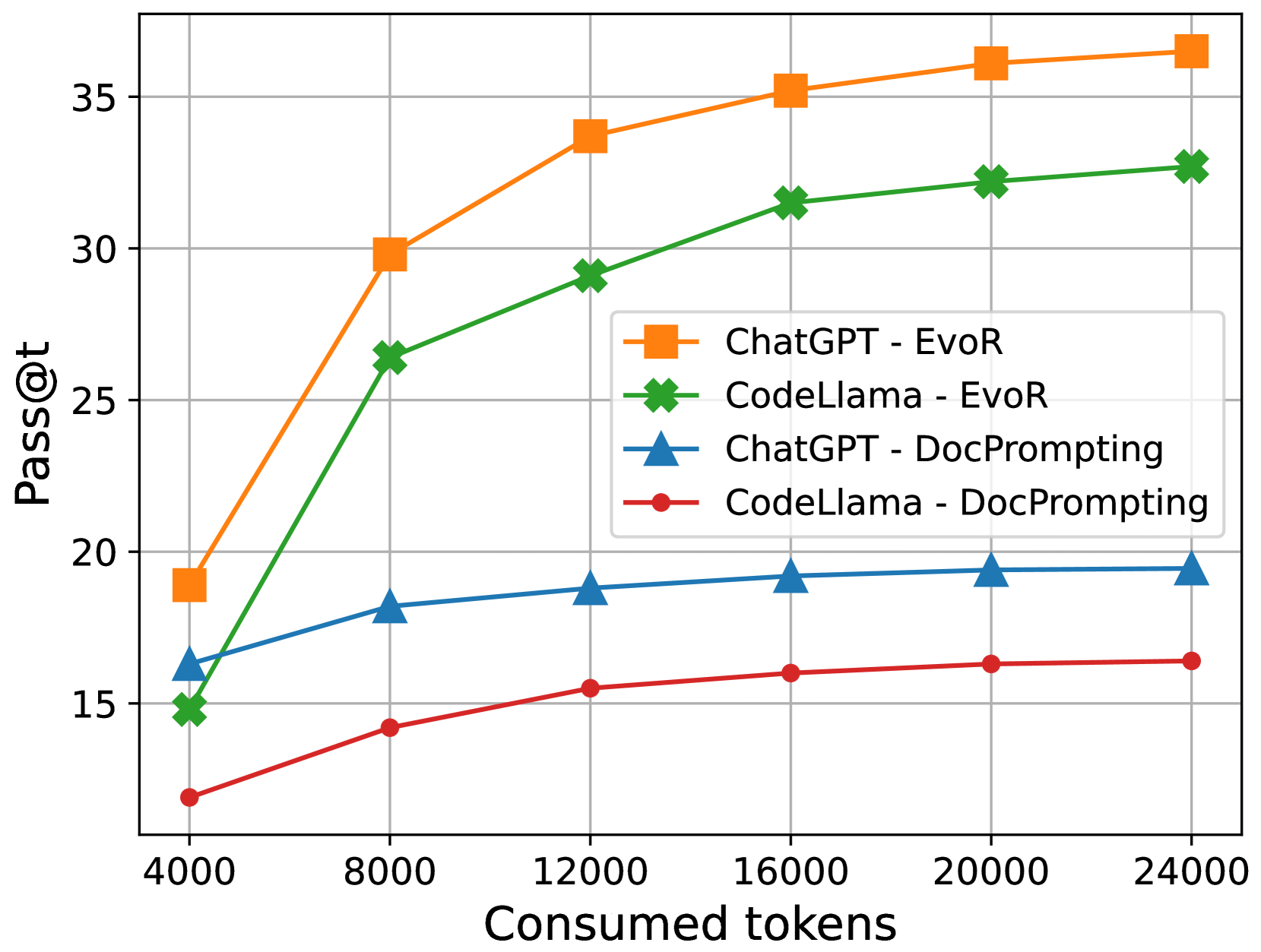
## Line Graph: Pass@t vs. Consumed Tokens
### Overview
The image is a line graph comparing the performance of four AI models (ChatGPT-EvoR, CodeLlama-EvoR, ChatGPT-DocPrompting, CodeLlama-DocPrompting) across varying token consumption levels. The y-axis measures "Pass@t" (a performance metric), while the x-axis represents "Consumed tokens" (input/output token counts). Four distinct data series are plotted with unique markers and colors.
### Components/Axes
- **X-axis**: "Consumed tokens" (4000–24000), incrementing by 4000.
- **Y-axis**: "Pass@t" (15–35), incrementing by 5.
- **Legend**: Located in the top-right corner, mapping:
- Orange squares: ChatGPT - EvoR
- Green crosses: CodeLlama - EvoR
- Blue triangles: ChatGPT - DocPrompting
- Red circles: CodeLlama - DocPrompting
### Detailed Analysis
1. **ChatGPT - EvoR (Orange Squares)**:
- Starts at ~19 at 4000 tokens.
- Rises sharply to ~30 at 8000 tokens.
- Continues upward to ~37 at 24000 tokens.
- **Trend**: Steepest slope, highest final value.
2. **CodeLlama - EvoR (Green Crosses)**:
- Begins at ~15 at 4000 tokens.
- Increases to ~33 at 24000 tokens.
- **Trend**: Consistent upward trajectory, second-highest performance.
3. **ChatGPT - DocPrompting (Blue Triangles)**:
- Starts at ~16 at 4000 tokens.
- Gradually rises to ~19 at 24000 tokens.
- **Trend**: Slowest growth among the four series.
4. **CodeLlama - DocPrompting (Red Circles)**:
- Begins at ~12 at 4000 tokens.
- Increases to ~16 at 24000 tokens.
- **Trend**: Flattest slope, lowest performance.
### Key Observations
- **Performance Hierarchy**: ChatGPT-EvoR > CodeLlama-EvoR > ChatGPT-DocPrompting > CodeLlama-DocPrompting.
- **Token Efficiency**: All models improve performance with more tokens, but ChatGPT-EvoR gains the most.
- **DocPrompting vs. EvoR**: EvoR models outperform DocPrompting counterparts by ~5–7 points at 24000 tokens.
- **CodeLlama Disparity**: CodeLlama-EvoR outperforms CodeLlama-DocPrompting by ~17 points at 24000 tokens.
### Interpretation
The data demonstrates that **EvoR prompting** significantly enhances performance across both models compared to **DocPrompting**. ChatGPT-EvoR achieves the highest Pass@t, suggesting superior optimization for token-intensive tasks. The steep rise in ChatGPT-EvoR’s performance between 4000–8000 tokens indicates a critical efficiency threshold. CodeLlama’s performance gap between prompting methods highlights the importance of prompt engineering for this model. The trends imply that larger token budgets disproportionately benefit EvoR-based approaches, potentially guiding resource allocation in AI deployment.