\n
## Line and Area Charts: Llama3.1-8B-Instruct Layer 1 Attention Head Analysis
### Overview
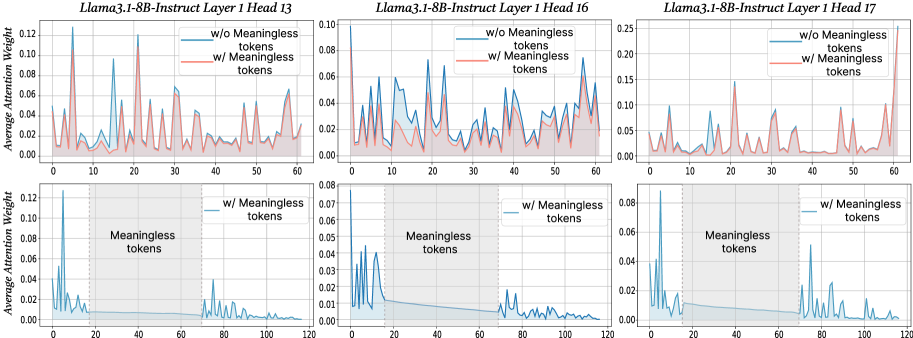
The image displays a 2x3 grid of six charts analyzing the average attention weight distribution across token positions for three specific attention heads (13, 16, and 17) in Layer 1 of the Llama3.1-8B-Instruct model. The top row compares model behavior with and without meaningless tokens, while the bottom row focuses solely on the scenario with meaningless tokens, highlighting a specific segment of the sequence.
### Components/Axes
* **Chart Titles (Top Row, Left to Right):**
* `Llama3.1-8B-Instruct Layer 1 Head 13`
* `Llama3.1-8B-Instruct Layer 1 Head 16`
* `Llama3.1-8B-Instruct Layer 1 Head 17`
* **Chart Titles (Bottom Row, Left to Right):** Same as above, corresponding to the same heads.
* **Y-Axis Label (All Charts):** `Average Attention Weight`
* **X-Axis Label (All Charts):** `Token Position`
* **Legends:**
* **Top Row Charts:** Located in the top-right corner of each plot area.
* Blue line: `w/o Meaningless tokens`
* Red line: `w/ Meaningless tokens`
* **Bottom Row Charts:** Located in the top-right corner of each plot area.
* Blue filled area: `w/ Meaningless tokens`
* **Axis Scales:**
* **Top Row X-Axis:** 0 to 60, with major ticks every 10 units.
* **Bottom Row X-Axis:** 0 to 120, with major ticks every 20 units.
* **Y-Axis Scales (Vary by Head):**
* Head 13 (Top & Bottom): 0.00 to 0.12
* Head 16 (Top): 0.00 to 0.10
* Head 16 (Bottom): 0.00 to 0.08
* Head 17 (Top): 0.00 to 0.25
* Head 17 (Bottom): 0.00 to 0.08
* **Annotations (Bottom Row Charts):**
* A gray shaded region spans from approximately token position 20 to 70.
* Vertical dashed lines mark the boundaries of this region at positions ~20 and ~70.
* Text label `Meaningless tokens` is centered within this shaded region.
### Detailed Analysis
**Top Row (Comparison: w/o vs. w/ Meaningless Tokens):**
* **Head 13:** The blue line (`w/o`) shows high volatility with sharp peaks exceeding 0.12 at positions ~5, ~15, and ~25. The red line (`w/`) follows a similar pattern but with generally lower peak magnitudes (max ~0.08) and appears slightly smoothed.
* **Head 16:** The blue line (`w/o`) is highly variable, with multiple peaks between 0.04 and 0.08. The red line (`w/`) is significantly dampened, staying mostly below 0.04, with a much flatter profile.
* **Head 17:** The blue line (`w/o`) exhibits extreme spikes, with the highest peak reaching ~0.25 near position 55. The red line (`w/`) is dramatically flattened, remaining below 0.05 for the entire sequence, indicating a massive reduction in attention weight variance.
**Bottom Row (Focus on w/ Meaningless Tokens):**
* **General Pattern (All Heads):** Attention weight is concentrated at the very beginning (positions 0-10) and the very end (positions 70-120) of the sequence. The central region, corresponding to the `Meaningless tokens` segment (positions 20-70), shows near-zero attention weight.
* **Head 13:** Initial peak ~0.12 at position ~2. A secondary, smaller cluster of peaks appears after position 70, maxing around 0.04.
* **Head 16:** Initial peak ~0.08 at position ~2. Very low activity (<0.01) in the middle. A small resurgence of peaks (max ~0.02) occurs after position 70.
* **Head 17:** Initial peak ~0.08 at position ~2. The middle section is flat. A distinct cluster of peaks appears after position 70, with the highest reaching ~0.05.
### Key Observations
1. **Dampening Effect:** The presence of meaningless tokens (`w/`) consistently reduces the magnitude and volatility of attention weights across all three heads compared to the `w/o` condition. This effect is most pronounced in Head 17.
2. **Attention Avoidance:** The bottom charts clearly demonstrate that the model's attention mechanism actively ignores the segment labeled as `Meaningless tokens`. Attention weight plummets to near zero within this region (positions 20-70).
3. **Boundary Focus:** Attention is heavily focused on the tokens immediately before and after the meaningless segment, suggesting the model uses these boundary tokens as anchors.
4. **Head-Specific Behavior:** While the general pattern holds, the specific attention profiles differ. Head 17 shows the most extreme reaction to meaningless tokens, going from the highest peaks (`w/o`) to one of the flattest profiles (`w/`).
### Interpretation
This data provides a technical visualization of how a large language model (Llama3.1-8B-Instruct) processes filler or meaningless content. The findings suggest:
* **Efficiency Mechanism:** The model appears to have an implicit mechanism to conserve its "attention budget." By dramatically reducing attention weights on meaningless tokens, it likely allocates more computational resources to semantically meaningful parts of the input.
* **Contextual Anchoring:** The strong attention at the boundaries of the meaningless segment indicates the model uses the surrounding meaningful context to frame its understanding, effectively "bridging" over the irrelevant information.
* **Architectural Insight:** The variation between heads (13, 16, 17) shows that not all attention heads are equal; some (like Head 17) may be more specialized in filtering noise or handling syntactic boundaries. This supports the concept of functional specialization within transformer attention layers.
* **Practical Implication:** For prompt engineering or model analysis, this indicates that inserting filler text may not simply "distract" the model in a uniform way but could trigger a specific, structured attention-reduction pattern, potentially altering the model's processing pathway in predictable ways.
**Language:** All text in the image is in English.