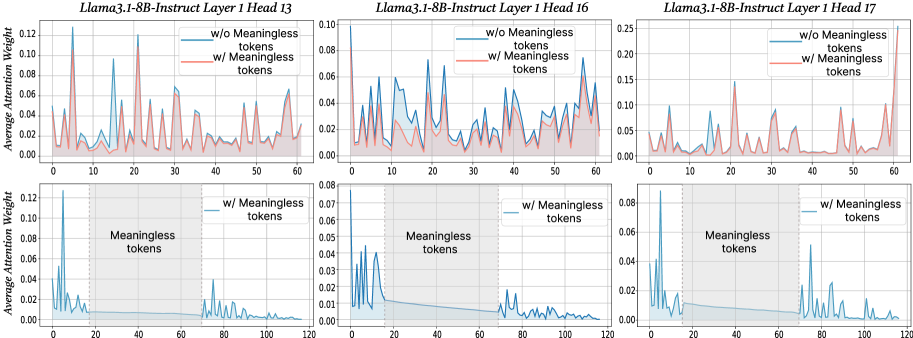
## Line Graphs: Llama3.1-8B-Instruct Attention Weights Across Layers and Heads
### Overview
The image contains six line graphs comparing average attention weights in a neural network model (Llama3.1-8B-Instruct) across three layers (Layer 1) and three heads (Heads 13, 16, 17). Each graph contrasts two conditions:
- **Blue line**: Attention weights **without meaningless tokens**
- **Red line**: Attention weights **with meaningless tokens**
The x-axis represents token positions (0–60), and the y-axis shows average attention weight (0–0.12). Shaded regions around lines indicate variability/confidence intervals.
---
### Components/Axes
1. **Top Row Graphs**
- **Graph 1**: Llama3.1-8B-Instruct Layer 1 Head 13
- **Graph 2**: Llama3.1-8B-Instruct Layer 1 Head 16
- **Graph 3**: Llama3.1-8B-Instruct Layer 1 Head 17
2. **Bottom Row Graphs**
- **Graph 4**: Llama3.1-8B-Instruct Layer 1 Head 13 (zoomed view, x-axis 0–120)
- **Graph 5**: Llama3.1-8B-Instruct Layer 1 Head 16 (zoomed view, x-axis 0–120)
- **Graph 6**: Llama3.1-8B-Instruct Layer 1 Head 17 (zoomed view, x-axis 0–120)
3. **Axes**
- **X-axis**: Token Position (0–60 in main graphs; 0–120 in zoomed graphs)
- **Y-axis**: Average Attention Weight (0–0.12)
4. **Legends**
- **Blue**: "w/o Meaningless tokens"
- **Red**: "w/ Meaningless tokens"
- Positioned in the **top-right corner** of each graph.
---
### Detailed Analysis
#### Graph 1 (Layer 1 Head 13)
- **Blue line (w/o tokens)**: Peaks at token 5 (~0.12), token 25 (~0.08), and token 55 (~0.06).
- **Red line (w/ tokens)**: Peaks at token 5 (~0.14), token 25 (~0.10), and token 55 (~0.08).
- **Shaded regions**: Wider for red line, indicating higher variability with tokens.
#### Graph 2 (Layer 1 Head 16)
- **Blue line**: Peaks at token 10 (~0.09), token 30 (~0.07), and token 50 (~0.05).
- **Red line**: Peaks at token 10 (~0.11), token 30 (~0.09), and token 50 (~0.07).
- **Shaded regions**: Consistent width, suggesting stable variability.
#### Graph 3 (Layer 1 Head 17)
- **Blue line**: Peaks at token 15 (~0.10), token 45 (~0.06), and token 55 (~0.04).
- **Red line**: Peaks at token 15 (~0.13), token 45 (~0.08), and token 55 (~0.10).
- **Shaded regions**: Narrower for blue line, indicating lower variability without tokens.
#### Zoomed Graphs (4–6)
- **Graph 4 (Head 13)**:
- Blue line drops sharply after token 20, remaining near 0.02.
- Red line shows a secondary peak at token 80 (~0.04).
- **Graph 5 (Head 16)**:
- Blue line has a minor peak at token 70 (~0.03).
- Red line shows a sharp drop after token 20, stabilizing near 0.01.
- **Graph 6 (Head 17)**:
- Blue line has a sustained low value (~0.01–0.02) after token 20.
- Red line exhibits a secondary peak at token 90 (~0.05).
---
### Key Observations
1. **Peak Attention**:
- Red lines (with tokens) consistently show **higher peaks** than blue lines in the same token positions (e.g., token 5 in Head 13: 0.14 vs. 0.12).
2. **Variability**:
- Shaded regions are wider for red lines, suggesting **greater uncertainty** in attention weights when meaningless tokens are present.
3. **Secondary Peaks**:
- Zoomed graphs reveal **additional attention spikes** in red lines at later token positions (e.g., token 80 in Head 13, token 90 in Head 17).
4. **Decay Patterns**:
- Blue lines (w/o tokens) show faster decay in attention weights after initial peaks compared to red lines.
---
### Interpretation
1. **Impact of Meaningless Tokens**:
- The presence of meaningless tokens increases attention weights in critical positions (e.g., token 5, 15), potentially indicating the model treats them as **distractors** or **contextual anchors**.
2. **Model Robustness**:
- Wider shaded regions for red lines suggest the model’s attention is **less stable** when processing noisy inputs, which could affect performance on tasks requiring focus on meaningful tokens.
3. **Secondary Attention Spikes**:
- Late-token peaks in red lines (e.g., token 80, 90) may reflect the model’s attempt to **recover context** after encountering irrelevant tokens.
4. **Layer-Specific Behavior**:
- Head 17 (Graph 3/6) shows the most pronounced difference between conditions, implying this head is **more sensitive to token relevance**.
---
### Technical Notes
- **Language**: All text is in English.
- **Uncertainty**: Values are approximate (e.g., "~0.12") due to lack of exact numerical labels.
- **Spatial Grounding**: Legends are consistently placed in the top-right corner; shaded regions align with line colors.