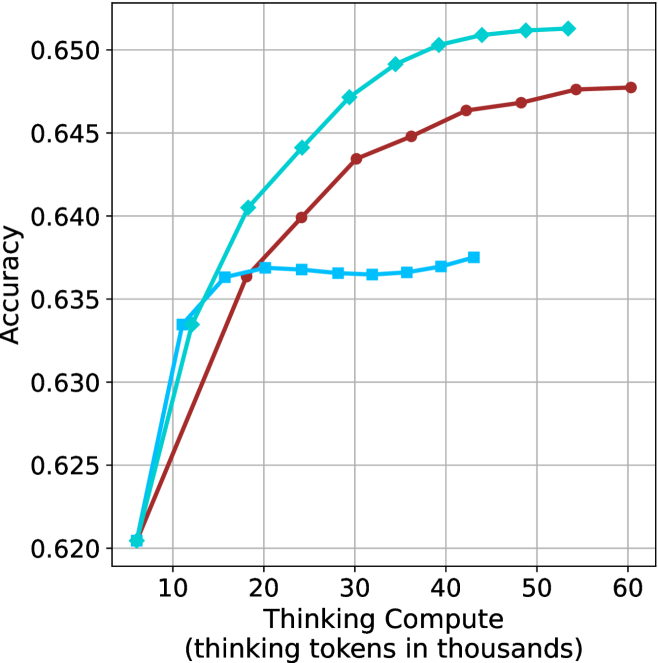
## Line Graph: Accuracy vs Thinking Compute (Tokens in Thousands)
### Overview
The graph illustrates the relationship between computational resources (thinking tokens in thousands) and accuracy across three variables: Thinking Compute, Model Size, and Prompt Length. Three distinct lines represent these variables, with accuracy measured on the y-axis (0.620–0.650) and thinking tokens on the x-axis (10–60k).
### Components/Axes
- **X-axis**: "Thinking Compute (thinking tokens in thousands)"
- Scale: 10 → 60 (in thousands)
- Position: Bottom of graph
- **Y-axis**: "Accuracy"
- Scale: 0.620 → 0.650
- Position: Left side of graph
- **Legend**: Top-right corner
- Labels:
- Teal: "Thinking Compute"
- Red: "Model Size"
- Blue: "Prompt Length"
### Detailed Analysis
1. **Thinking Compute (Teal Line)**
- Starts at (10k, 0.620) and rises steadily to (60k, 0.650).
- Slope: Linear increase (~0.0005 accuracy per 1k tokens).
- Key point: Highest accuracy across all token ranges.
2. **Model Size (Red Line)**
- Begins at (10k, 0.620) and rises sharply to (30k, 0.645), then plateaus.
- Slope: Steeper than teal line initially (~0.0015 accuracy per 1k tokens up to 30k).
- Key point: Accuracy stabilizes after 30k tokens.
3. **Prompt Length (Blue Line)**
- Starts at (10k, 0.635) and remains flat until 20k tokens, then increases slightly to (60k, 0.637).
- Slope: Minimal (~0.0001 accuracy per 1k tokens after 20k).
- Key point: Lowest accuracy overall, with delayed improvement.
### Key Observations
- **Accuracy Trends**:
- Thinking Compute consistently outperforms other variables.
- Model Size shows diminishing returns after 30k tokens.
- Prompt Length has negligible impact until 20k tokens.
- **Outliers**:
- Blue line (Prompt Length) exhibits a plateau (10k–20k tokens) and delayed growth.
- Red line (Model Size) plateaus abruptly at 30k tokens.
### Interpretation
The data suggests that **increasing thinking compute (tokens)** is the most effective way to improve accuracy, with linear scalability. Model size contributes significantly but plateaus, indicating diminishing returns at higher token counts. Prompt length has minimal impact, suggesting it is less critical than compute resources. This aligns with findings in large language model optimization, where compute efficiency often outweighs static model or prompt design. The abrupt plateau in Model Size accuracy may reflect architectural limits or optimization thresholds in the evaluated systems.