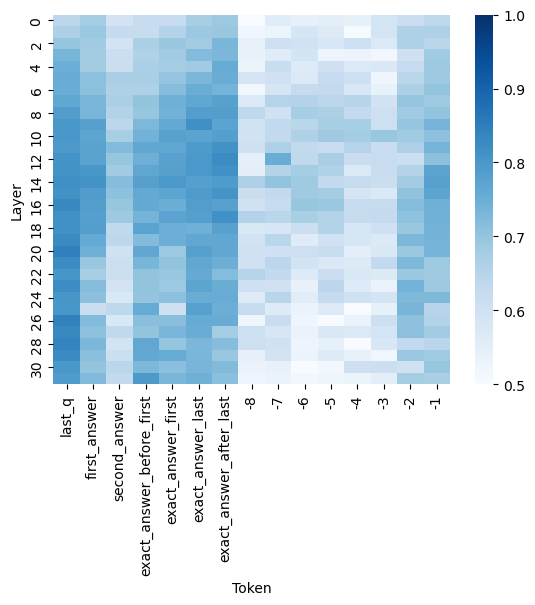
## Heatmap: Layer Activation vs. Token Influence
### Overview
The image presents a heatmap visualizing the relationship between layers in a neural network and the influence of specific tokens. The heatmap uses a color gradient to represent values ranging from approximately 0.5 to 1.0, with darker blues indicating lower values and lighter blues/whites indicating higher values. The x-axis represents tokens, and the y-axis represents layers.
### Components/Axes
* **X-axis (Horizontal):** "Token" with the following categories: "last\_q", "first\_answer", "second\_answer", "exact\_answer\_before\_first", "exact\_answer\_first", "exact\_answer\_after\_last", and tokens numbered -8 to -1.
* **Y-axis (Vertical):** "Layer" ranging from 2 to 30, with increments of 2.
* **Color Scale (Right):** Represents the value associated with each cell in the heatmap. The scale ranges from 0.5 (dark blue) to 1.0 (dark red). The scale is marked with values 0.5, 0.6, 0.7, 0.8, 0.9, and 1.0.
* **Legend:** Located on the right side of the image, providing the color mapping for the heatmap values.
### Detailed Analysis
The heatmap shows varying levels of activation/influence between layers and tokens. Here's a breakdown of observed values, noting approximate values due to the resolution of the image:
* **Token "last\_q":** Shows relatively low values (around 0.55-0.6) across most layers, with a slight increase towards layer 30 (approximately 0.65).
* **Token "first\_answer":** Displays a strong activation in layers 2-10, peaking around 0.9-1.0. The activation decreases as the layer number increases, falling to approximately 0.6-0.7 by layer 30.
* **Token "second\_answer":** Similar to "first\_answer", it exhibits high activation in lower layers (around 0.9-1.0) and a decreasing trend as the layer number increases, reaching approximately 0.6-0.7 at layer 30.
* **Token "exact\_answer\_before\_first":** Shows moderate activation (around 0.7-0.8) in layers 2-16, then decreases to approximately 0.6 by layer 30.
* **Token "exact\_answer\_first":** Displays a peak activation around 0.9-1.0 in layers 6-12, then decreases to approximately 0.6-0.7 by layer 30.
* **Token "exact\_answer\_after\_last":** Shows relatively low activation (around 0.55-0.65) across all layers.
* **Tokens -8 to -1:** These tokens generally exhibit lower activation values (around 0.55-0.7) across all layers, with some minor fluctuations. Token -1 shows a slight increase in activation around layer 26 (approximately 0.75).
**Trend Verification:**
* For "first\_answer" and "second\_answer", the heatmap visually confirms a downward sloping trend as the layer number increases.
* "last\_q" and "exact\_answer\_after\_last" show relatively flat activation across layers.
* The numbered tokens (-8 to -1) show generally low and stable activation.
### Key Observations
* The tokens "first\_answer" and "second\_answer" have the highest activation values in the earlier layers (2-10).
* Activation generally decreases as the layer number increases for most tokens.
* "last\_q" and "exact\_answer\_after\_last" consistently show lower activation values compared to other tokens.
* There is a slight increase in activation for token -1 around layer 26.
### Interpretation
This heatmap likely represents the importance or contribution of different tokens to the activation of various layers within a neural network model, potentially a question-answering system. The decreasing activation of "first\_answer" and "second\_answer" as the layer number increases suggests that the initial processing of the answer is more prominent in the earlier layers, while later layers may focus on refining or integrating this information. The lower activation of "last\_q" and "exact\_answer\_after\_last" could indicate that these tokens are less crucial for the model's overall processing. The heatmap provides insights into how the model processes information at different stages, highlighting which tokens are most influential at each layer. The slight activation peak for token -1 at layer 26 could be an anomaly or indicate a specific feature being processed at that layer. Further investigation would be needed to understand the specific meaning of these tokens within the context of the model.