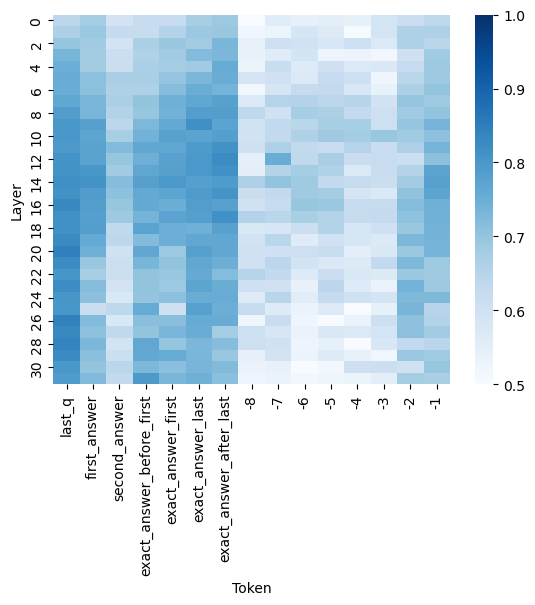
## Heatmap: Token-Layer Attention Distribution
### Overview
The image is a heatmap visualizing the distribution of attention weights or similarity scores between input tokens and transformer model layers. The x-axis represents input tokens (e.g., question/answer components), while the y-axis represents model layers (0–30). Darker blue shades indicate higher values (closer to 1.0), and lighter shades represent lower values (closer to 0.5).
---
### Components/Axes
- **X-axis (Tokens)**:
- `last_q`
- `first_answer`
- `second_answer`
- `exact_answer_before_first`
- `exact_answer_first`
- `exact_answer_last`
- `exact_answer_after_last`
- **Y-axis (Layers)**:
- Layer indices: 0 (bottom) to 30 (top)
- **Color Scale**:
- Legend on the right: Dark blue (1.0) to light gray (0.5)
- **Spatial Layout**:
- Legend positioned vertically on the right side of the heatmap.
- Tokens labeled at the bottom, layers labeled on the left.
---
### Detailed Analysis
1. **Token-Layer Patterns**:
- **`last_q`**: High values (dark blue) concentrated in layers 28–30, suggesting strong attention to the final question token in later layers.
- **`first_answer`**: Peaks in layers 12–16, with moderate values in layers 18–22.
- **`second_answer`**: Similar to `first_answer`, with peaks in layers 12–16 and 18–22.
- **`exact_answer_before_first`**: High values in layers 24–28, indicating late-layer focus.
- **`exact_answer_first`**: Peaks in layers 24–28, with gradual decline toward layer 30.
- **`exact_answer_last`**: Strongest values in layers 28–30, mirroring `last_q`.
- **`exact_answer_after_last`**: High values in layers 28–30, similar to `exact_answer_last`.
2. **Value Distribution**:
- Most tokens show elevated values in mid-to-late layers (12–30), with the highest concentrations in layers 24–30.
- Early layers (0–11) exhibit uniformly low values (<0.6) across all tokens.
---
### Key Observations
- **Layer-Specific Attention**:
- Early layers (0–11) show minimal engagement with all tokens, suggesting initial processing focuses on basic tokenization or positional encoding.
- Mid-layers (12–22) handle answer-related tokens (`first_answer`, `second_answer`), while late layers (24–30) dominate for question and exact answer tokens.
- **Token Hierarchy**:
- `last_q` and `exact_answer_last`/`after_last` share the highest attention in the final layers, implying the model prioritizes terminal input components for final output generation.
- `exact_answer_before_first` and `exact_answer_first` show slightly earlier peaks (layers 24–28), possibly reflecting intermediate processing of answer boundaries.
---
### Interpretation
This heatmap reveals how a transformer model allocates attention across input tokens at different processing depths:
1. **Early Layers (0–11)**: Likely handle low-level features (e.g., token embeddings, positional encoding) with minimal token-specific attention.
2. **Mid-Layers (12–22)**: Focus on answer-related tokens (`first_answer`, `second_answer`), suggesting these layers refine contextual relationships between question and answer components.
3. **Late Layers (24–30)**: Dominated by question and exact answer tokens, indicating these layers integrate high-level semantic understanding, particularly for terminal input elements.
The concentration of high values in late layers for `last_q` and `exact_answer_last`/`after_last` suggests the model’s final output (e.g., generated answers) is heavily influenced by the last question and precise answer tokens. This aligns with transformer architectures, where deeper layers capture abstract, context-rich representations.
**Notable Anomaly**: The `exact_answer_before_first` token shows elevated attention in layers 24–28 but declines sharply in layer 30, unlike other late-layer tokens. This could indicate a transitional role in answer boundary detection before final refinement in later layers.
---
**Conclusion**: The heatmap demonstrates a clear progression of attention from low-level processing in early layers to high-level semantic integration in late layers, with terminal tokens (`last_q`, `exact_answer_last/after_last`) receiving the strongest focus in the model’s final stages.