TECHNICAL ASSET FINGERPRINT
41bf14ef1bc05df1984737fc
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
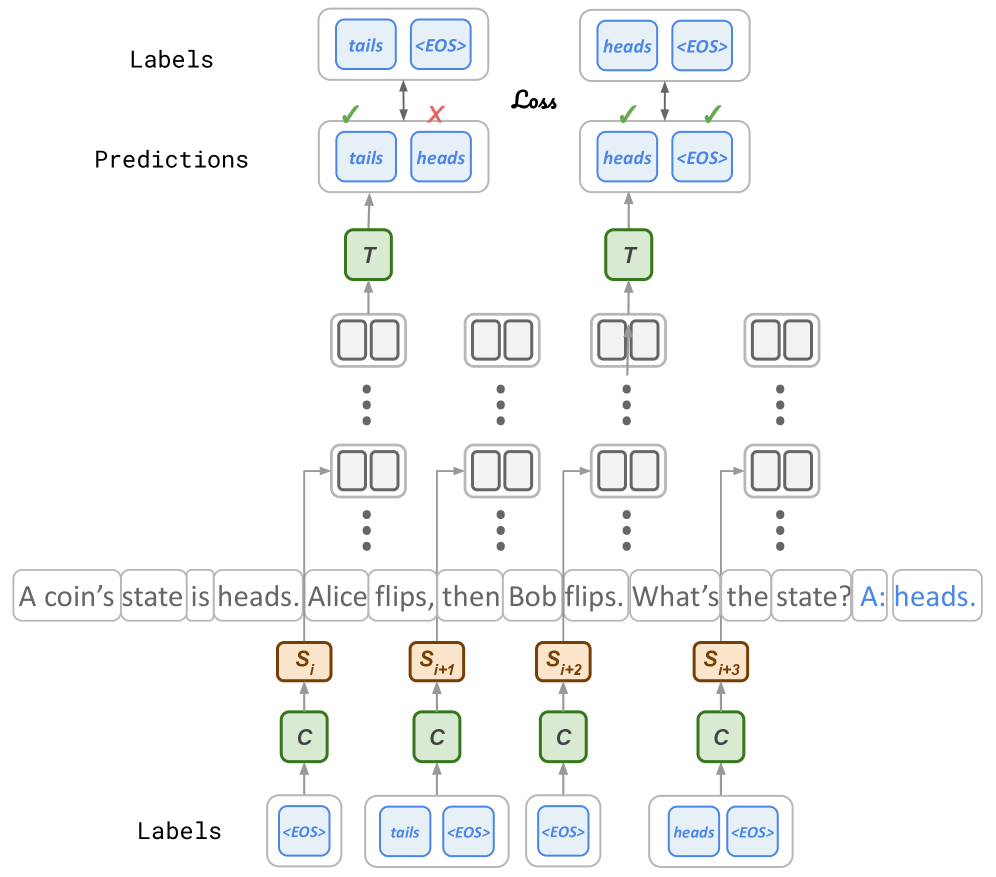
## Diagram: Sequence Prediction Model with Loss Calculation
### Overview
This image is a technical diagram illustrating a sequence-to-sequence prediction model, likely a transformer or recurrent neural network, processing a reasoning task about coin flips. The diagram shows the flow from input tokens through model components to predictions, which are then compared to ground truth labels to compute a loss. The primary language is English.
### Components/Axes
The diagram is structured vertically into three main sections:
1. **Top Section (Output & Loss):**
* **Labels (Top Row):** Two sets of target sequences.
* Left: `["tails", "<EOS>"]`
* Right: `["heads", "<EOS>"]`
* **Predictions (Second Row):** The model's predicted sequences.
* Left: `["tails", "heads"]`
* Right: `["heads", "<EOS>"]`
* **Loss Calculation:** Arrows connect corresponding positions between Labels and Predictions. Green checkmarks (✓) indicate correct predictions, while a red cross (✗) indicates an incorrect prediction. The word "Loss" is written between the two comparison sets, signifying the calculation of error.
2. **Middle Section (Model Architecture):**
* **T Blocks:** Two green rectangular blocks labeled "T" (likely representing Transformer decoder layers or a similar processing unit). They receive input from below and output to the prediction layer above.
* **Intermediate Representations:** Between the T blocks and the input sequence, there are multiple rows of paired, empty rectangular boxes (e.g., `[] []`), connected by vertical ellipses (`⋮`). These represent hidden states or intermediate token representations across multiple layers or time steps.
* **Input Sequence:** A horizontal row of text tokens forming a question and answer:
`A coin's state is heads. Alice flips, then Bob flips. What's the state? A: heads.`
The final token "heads." is highlighted in blue.
3. **Bottom Section (Input Processing & Auxiliary Labels):**
* **S Blocks:** Four brown rectangular blocks labeled `S_i`, `S_{i+1}`, `S_{i+2}`, `S_{i+3}`. These are positioned below specific tokens in the input sequence ("heads.", "flips,", "flips.", "state?") and likely represent state encodings or special token embeddings.
* **C Blocks:** Four green rectangular blocks labeled "C" (likely representing encoder layers or context processors). Each `C` block feeds into a corresponding `S` block above it.
* **Labels (Bottom Row):** Another set of target sequences, aligned with the `C` blocks.
* Under first `C`: `["<EOS>"]`
* Under second `C`: `["tails", "<EOS>"]`
* Under third `C`: `["<EOS>"]`
* Under fourth `C`: `["heads", "<EOS>"]`
### Detailed Analysis
* **Task:** The model is solving a multi-step reasoning problem: Given an initial state ("heads"), two actions ("Alice flips", "Bob flips"), it must predict the final state. The correct answer is "heads" (since two flips return the coin to its original state).
* **Prediction Flow:**
1. The input text sequence is processed by the "C" (context/encoder) blocks.
2. State information (`S_i` to `S_{i+3}`) is derived and fed into the intermediate representation layers.
3. The "T" (transformer/decoder) blocks generate output predictions autoregressively.
* **Loss Calculation Detail:**
* **Left Comparison:** The model's first predicted sequence is `["tails", "heads"]`. The target label is `["tails", "<EOS>"]`.
* First token: Prediction "tails" matches label "tails" (✓).
* Second token: Prediction "heads" does **not** match label "<EOS>" (✗). This is an error; the model predicted an extra token instead of ending the sequence.
* **Right Comparison:** The model's second predicted sequence is `["heads", "<EOS>"]`. The target label is `["heads", "<EOS>"]`.
* First token: Prediction "heads" matches label "heads" (✓).
* Second token: Prediction "<EOS>" matches label "<EOS>" (✓). This is a correct prediction.
* **Text Transcription (All Visible Text):**
* `Labels`, `Predictions`, `Loss`
* `tails`, `<EOS>`, `heads`
* `T`
* `A coin's state is heads. Alice flips, then Bob flips. What's the state? A: heads.`
* `S_i`, `S_{i+1}`, `S_{i+2}`, `S_{i+3}`
* `C`
### Key Observations
1. **Error Highlighted:** The diagram explicitly shows a prediction error where the model fails to generate the `<EOS>` (End of Sequence) token at the correct time, instead generating a content token ("heads").
2. **Dual Label Sets:** There are two distinct sets of "Labels" – one at the top (for the final output sequence) and one at the bottom (likely for auxiliary training signals or intermediate state prediction).
3. **Architectural Abstraction:** The diagram uses abstract blocks ("C", "S", "T") rather than specific layer names, indicating it's a conceptual model of a sequence processing architecture.
4. **Task-Specific Example:** The coin flip problem is a classic test for logical reasoning and state tracking in AI models.
### Interpretation
This diagram serves as a pedagogical or technical illustration of how a sequence prediction model is trained using supervised learning. It demonstrates the core mechanism of comparing generated sequences against ground truth to compute a loss, which is then used to update model parameters.
The specific example highlights a common challenge in sequence generation: **proper sequence termination**. The model correctly identifies the final state ("heads") but incorrectly continues generation, failing to predict the `<EOS>` token. This suggests the model may have learned the content of the answer but not the structural rule for when to stop generating.
The presence of two label sets implies a complex training objective, possibly involving:
* **Teacher Forcing:** The bottom labels might be used to train the encoder ("C" blocks) or intermediate states.
* **Multi-Task Learning:** The model could be trained to predict both the final answer and auxiliary information.
Overall, the image encapsulates the flow of data, the structure of a modern neural network for reasoning tasks, and the fundamental process of error calculation that drives model learning. It visually answers the question: "How does a model learn to answer a question, and how do we know when it's wrong?"
DECODING INTELLIGENCE...