\n
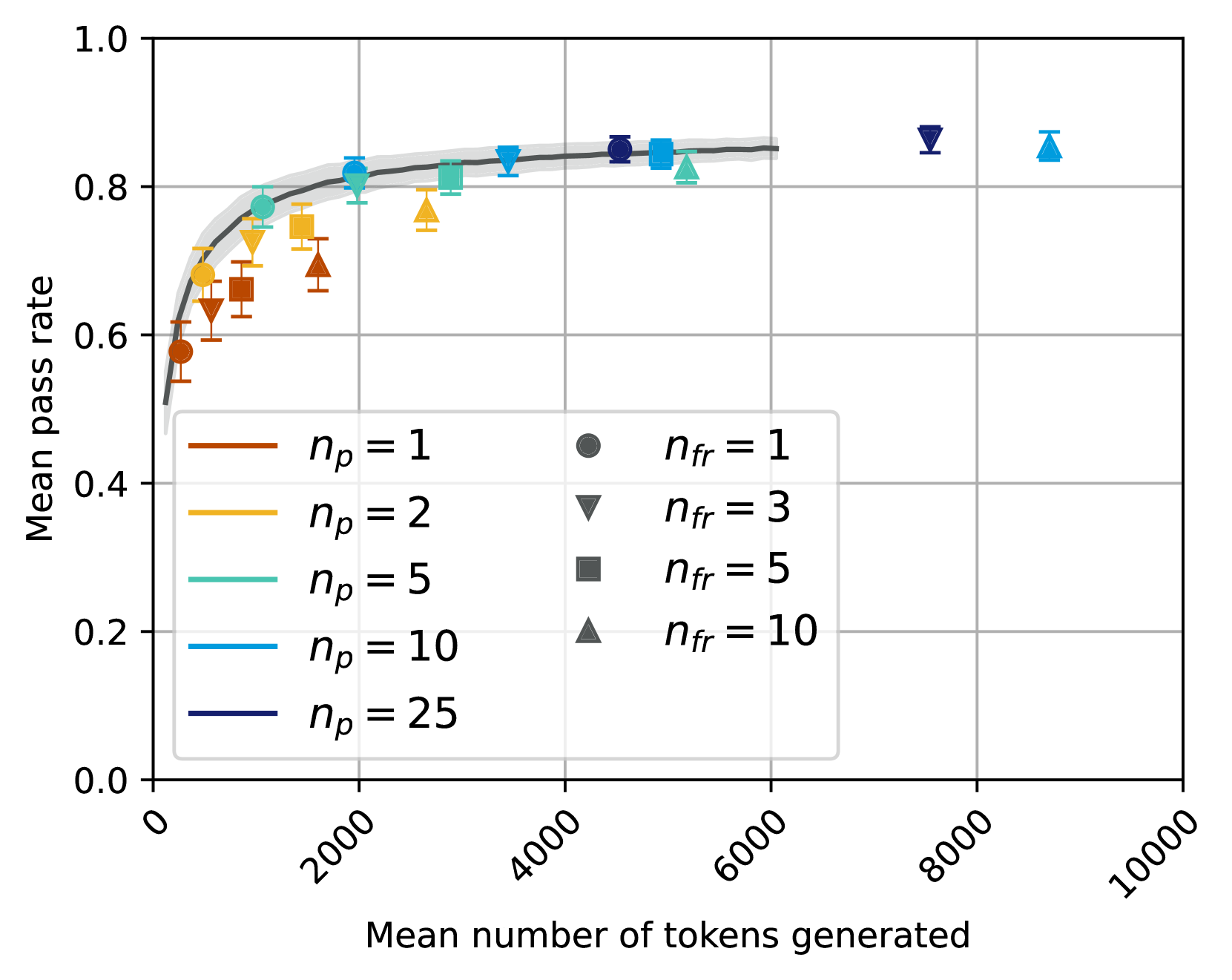
## Chart: Mean Pass Rate vs. Mean Number of Tokens Generated
### Overview
The image presents a line chart illustrating the relationship between the mean number of tokens generated and the mean pass rate, under varying conditions of `n_p` (number of prompts) and `n_fr` (number of failed responses). Error bars are included to represent the variability in the data.
### Components/Axes
* **X-axis:** "Mean number of tokens generated" ranging from 0 to 10000, with tick marks at 0, 2000, 4000, 6000, 8000, and 10000.
* **Y-axis:** "Mean pass rate" ranging from 0.0 to 1.0, with tick marks at 0.0, 0.2, 0.4, 0.6, 0.8, and 1.0.
* **Lines:** Represent different values of `n_p`: 1 (orange), 2 (light gray), 5 (teal), 10 (purple), and 25 (dark blue).
* **Markers:** Represent different values of `n_fr`: 1 (gray circle), 3 (gray downward triangle), 5 (dark gray square), and 10 (light gray upward triangle).
* **Legend:** Located in the bottom-left corner, detailing the mapping between line color and `n_p` value, and marker shape and `n_fr` value.
### Detailed Analysis
The chart displays the mean pass rate as a function of the mean number of tokens generated, with different lines representing different values of `n_p`. The markers indicate data points for different values of `n_fr`.
* **n_p = 1 (Orange Line):** Starts at approximately 0.62 at 0 tokens generated. The line initially rises steeply, reaching approximately 0.75 at 2000 tokens. It then plateaus, reaching approximately 0.82 at 4000 tokens and remaining relatively stable until 10000 tokens, where it is approximately 0.83. The error bars are relatively large at the beginning, decreasing as the number of tokens increases.
* **n_p = 2 (Light Gray Line):** Starts at approximately 0.65 at 0 tokens. It rises more gradually than the orange line, reaching approximately 0.78 at 2000 tokens. It continues to rise, reaching approximately 0.85 at 4000 tokens, and plateaus around 0.87-0.88 for the remainder of the range. Error bars are similar in size to the orange line.
* **n_p = 5 (Teal Line):** Starts at approximately 0.70 at 0 tokens. It rises quickly, reaching approximately 0.80 at 2000 tokens. It plateaus around 0.85-0.86 from 4000 tokens onwards. Error bars are smaller than the previous two lines.
* **n_p = 10 (Purple Line):** Starts at approximately 0.73 at 0 tokens. It rises rapidly, reaching approximately 0.83 at 2000 tokens. It plateaus around 0.88-0.89 from 4000 tokens onwards. Error bars are very small.
* **n_p = 25 (Dark Blue Line):** Starts at approximately 0.75 at 0 tokens. It rises quickly, reaching approximately 0.85 at 2000 tokens. It plateaus around 0.90-0.91 from 4000 tokens onwards. Error bars are the smallest of all lines.
**Markers (n_fr):**
* **n_fr = 1 (Gray Circle):** Located at approximately (8000, 0.88) and (10000, 0.89).
* **n_fr = 3 (Gray Downward Triangle):** Located at approximately (8000, 0.85) and (10000, 0.87).
* **n_fr = 5 (Dark Gray Square):** Located at approximately (8000, 0.83) and (10000, 0.85).
* **n_fr = 10 (Light Gray Upward Triangle):** Located at approximately (8000, 0.81) and (10000, 0.83).
### Key Observations
* As `n_p` increases, the mean pass rate generally increases, and the variability (as indicated by the error bars) decreases.
* All lines converge towards a plateau around a mean pass rate of 0.85-0.91 as the number of tokens generated increases.
* The markers indicate that as `n_fr` increases, the mean pass rate decreases at higher token counts (8000-10000).
### Interpretation
The data suggests that increasing the number of prompts (`n_p`) generally improves the mean pass rate, particularly at lower token counts. However, the improvement diminishes as the number of tokens generated increases, indicating a point of diminishing returns. The plateau observed for all `n_p` values suggests that there is a limit to how much the pass rate can be improved by simply increasing the number of prompts.
The decreasing pass rate with increasing `n_fr` at higher token counts suggests that a higher number of failed responses negatively impacts the overall performance, especially when a large number of tokens have already been generated. This could be due to the model getting "stuck" or generating irrelevant content after multiple failures.
The error bars provide a measure of the uncertainty in the data. The decreasing error bars with increasing token counts for each `n_p` value suggest that the model's performance becomes more consistent as it generates more tokens. This could be because the model learns from its previous outputs and becomes more confident in its responses.