\n
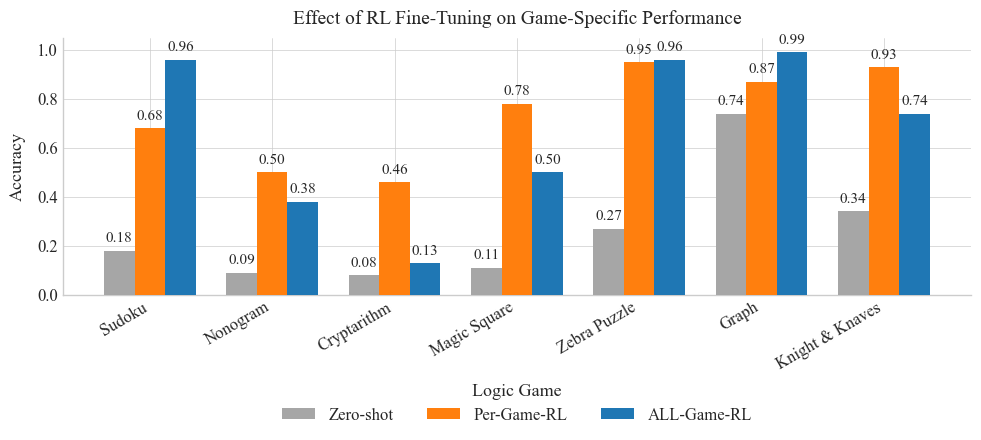
## Bar Chart: Effect of RL Fine-Tuning on Game-Specific Performance
### Overview
This bar chart compares the accuracy of a model on several logic games under three different training conditions: Zero-shot, Per-Game-RL (Reinforcement Learning), and ALL-Game-RL. The accuracy is measured on a scale from 0.0 to 1.0. The chart displays the performance for Sudoku, Nonogram, Cryptarithm, Magic Square, Zebra Puzzle, Graph, and Knight & Knaves.
### Components/Axes
* **Title:** Effect of RL Fine-Tuning on Game-Specific Performance
* **X-axis:** Logic Game (Sudoku, Nonogram, Cryptarithm, Magic Square, Zebra Puzzle, Graph, Knight & Knaves)
* **Y-axis:** Accuracy (Scale from 0.0 to 1.0)
* **Legend:**
* Zero-shot (Grey)
* Per-Game-RL (Orange)
* ALL-Game-RL (Blue)
### Detailed Analysis
The chart consists of groups of three bars for each logic game, representing the accuracy achieved under each training condition.
**Sudoku:**
* Zero-shot: Approximately 0.18
* Per-Game-RL: Approximately 0.68
* ALL-Game-RL: Approximately 0.96
**Nonogram:**
* Zero-shot: Approximately 0.09
* Per-Game-RL: Approximately 0.38
* ALL-Game-RL: Approximately 0.50
**Cryptarithm:**
* Zero-shot: Approximately 0.08
* Per-Game-RL: Approximately 0.46
* ALL-Game-RL: Approximately 0.13
**Magic Square:**
* Zero-shot: Approximately 0.11
* Per-Game-RL: Approximately 0.78
* ALL-Game-RL: Approximately 0.50
**Zebra Puzzle:**
* Zero-shot: Approximately 0.27
* Per-Game-RL: Approximately 0.50
* ALL-Game-RL: Approximately 0.95
**Graph:**
* Zero-shot: Approximately 0.74
* Per-Game-RL: Approximately 0.87
* ALL-Game-RL: Approximately 0.99
**Knight & Knaves:**
* Zero-shot: Approximately 0.34
* Per-Game-RL: Approximately 0.74
* ALL-Game-RL: Approximately 0.93
### Key Observations
* **General Trend:** Across all games, the ALL-Game-RL consistently achieves the highest accuracy, followed by Per-Game-RL, and then Zero-shot.
* **Significant Improvement:** RL fine-tuning (both Per-Game and ALL-Game) significantly improves accuracy compared to the Zero-shot baseline for most games.
* **Cryptarithm Anomaly:** ALL-Game-RL performs *worse* on Cryptarithm than Zero-shot.
* **High Performance:** Sudoku, Graph, and Knight & Knaves show very high accuracy with ALL-Game-RL, approaching 1.0.
* **Low Performance:** Nonogram and Cryptarithm consistently have the lowest accuracy scores across all training methods.
### Interpretation
The data strongly suggests that Reinforcement Learning fine-tuning is highly effective in improving the performance of the model on these logic games. The ALL-Game-RL strategy, where the model is trained on all games simultaneously, generally outperforms the Per-Game-RL strategy, indicating a benefit from transfer learning between games.
The anomaly with Cryptarithm is interesting. It could indicate that the ALL-Game-RL training process negatively interferes with the model's ability to solve Cryptarithm problems, potentially due to conflicting learned patterns. Alternatively, it could be a statistical fluctuation or a limitation of the model's architecture.
The varying levels of performance across different games suggest that some games are inherently easier for the model to learn than others. Sudoku, Graph, and Knight & Knaves appear to be relatively straightforward, while Nonogram and Cryptarithm pose greater challenges. The high accuracy achieved on these games with ALL-Game-RL suggests that the model is capable of learning complex reasoning patterns when provided with sufficient training data and a suitable learning strategy.