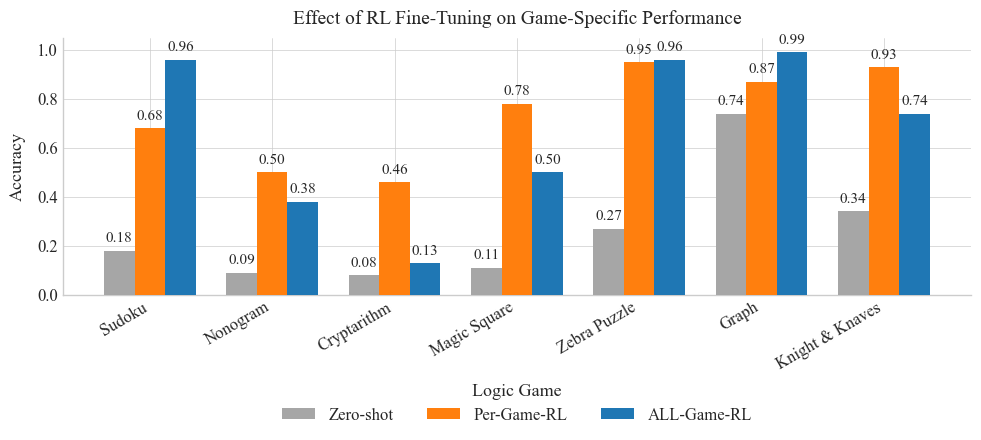
## Bar Chart: Effect of RL Fine-Tuning on Game-Specific Performance
### Overview
The chart compares the accuracy of three RL fine-tuning approaches (Zero-shot, Per-Game-RL, ALL-Game-RL) across seven logic games. Accuracy values range from 0.0 to 1.0, with distinct color-coded bars for each method.
### Components/Axes
- **X-axis (Logic Game)**: Sudoku, Nonogram, Cryptarithm, Magic Square, Zebra Puzzle, Graph, Knight & Knaves
- **Y-axis (Accuracy)**: 0.0 to 1.0 in increments of 0.2
- **Legend**:
- Gray: Zero-shot
- Orange: Per-Game-RL
- Blue: ALL-Game-RL
- **Title**: Positioned at the top center
### Detailed Analysis
1. **Sudoku**
- Zero-shot: 0.18 (gray)
- Per-Game-RL: 0.68 (orange)
- ALL-Game-RL: 0.96 (blue)
2. **Nonogram**
- Zero-shot: 0.09 (gray)
- Per-Game-RL: 0.50 (orange)
- ALL-Game-RL: 0.38 (blue)
3. **Cryptarithm**
- Zero-shot: 0.08 (gray)
- Per-Game-RL: 0.46 (orange)
- ALL-Game-RL: 0.13 (blue)
4. **Magic Square**
- Zero-shot: 0.11 (gray)
- Per-Game-RL: 0.78 (orange)
- ALL-Game-RL: 0.50 (blue)
5. **Zebra Puzzle**
- Zero-shot: 0.27 (gray)
- Per-Game-RL: 0.95 (orange)
- ALL-Game-RL: 0.96 (blue)
6. **Graph**
- Zero-shot: 0.74 (gray)
- Per-Game-RL: 0.87 (orange)
- ALL-Game-RL: 0.99 (blue)
7. **Knight & Knaves**
- Zero-shot: 0.34 (gray)
- Per-Game-RL: 0.93 (orange)
- ALL-Game-RL: 0.74 (blue)
### Key Observations
- **ALL-Game-RL** consistently achieves the highest accuracy across all games, with **Graph** (0.99) and **Zebra Puzzle** (0.96) showing near-perfect performance.
- **Zero-shot** performs poorly overall, with **Cryptarithm** (0.08) and **Nonogram** (0.09) having the lowest values.
- **Per-Game-RL** outperforms Zero-shot in all cases but lags behind ALL-Game-RL in most games (e.g., Sudoku: 0.68 vs. 0.96).
- **Zebra Puzzle** and **Graph** show the smallest performance gap between Per-Game-RL and ALL-Game-RL (0.01 and 0.02, respectively).
### Interpretation
The data demonstrates that **ALL-Game-RL** significantly outperforms both Zero-shot and Per-Game-RL across all logic games, suggesting that a generalized fine-tuning approach (ALL-Game-RL) is more effective than game-specific tuning (Per-Game-RL) or no tuning (Zero-shot). Notably, **Graph** and **Zebra Puzzle** achieve near-perfect accuracy with ALL-Game-RL, indicating these games may have simpler patterns or more structured data. The stark contrast between Zero-shot and fine-tuned methods highlights the critical role of RL adaptation in improving performance. However, the superior performance of ALL-Game-RL raises questions about whether it overfits to specific game structures or benefits from a more robust training paradigm.