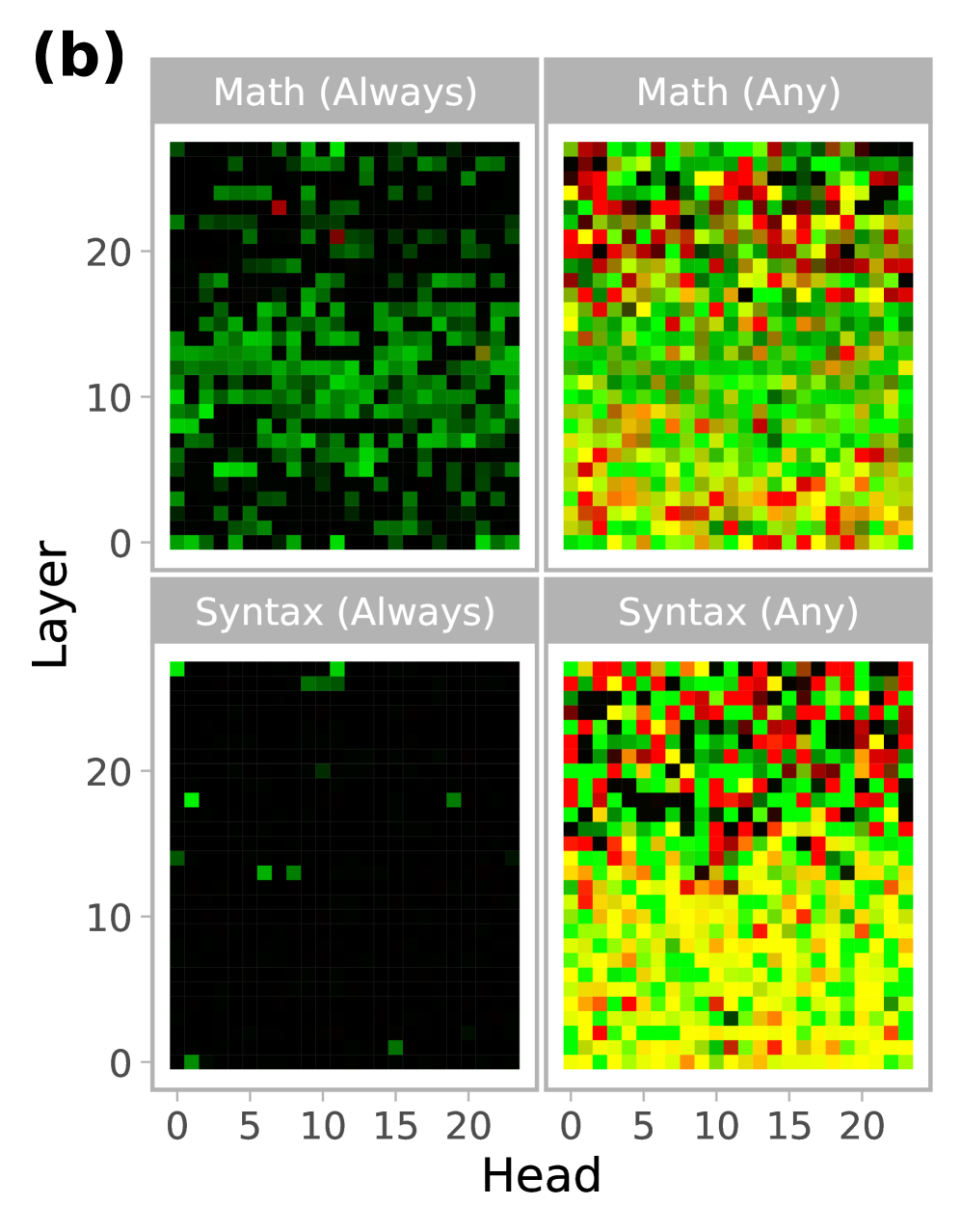
## Heatmaps: Attention Head Analysis
### Overview
The image presents four heatmaps, arranged in a 2x2 grid, visualizing attention head activity across layers. Each heatmap corresponds to a specific combination of task (Math or Syntax) and attention requirement ("Always" or "Any"). The heatmaps display the intensity of attention, likely representing the strength of the connection between heads and layers, using a color gradient.
### Components/Axes
* **X-axis:** "Head" - Ranges from 0 to approximately 21, representing the index of the attention head.
* **Y-axis:** "Layer" - Ranges from 0 to approximately 23, representing the layer number in a neural network.
* **Color Scale:** A gradient from dark blue (low attention) to red (high attention), passing through green and yellow.
* **Titles:**
* Top-Left: "Math (Always)"
* Top-Right: "Math (Any)"
* Bottom-Left: "Syntax (Always)"
* Bottom-Right: "Syntax (Any)"
* **Grid Layout:** 2 rows x 2 columns.
### Detailed Analysis or Content Details
**1. Math (Always)** (Top-Left)
* **Trend:** The heatmap shows a generally high level of attention across most layers and heads, with a concentration of high attention (red/yellow) in the middle layers (approximately layers 8-18) and a more dispersed pattern in the lower layers (0-8).
* **Data Points (Approximate):**
* Attention is consistently above the midpoint color (green) for most head/layer combinations.
* Highest attention values (red) are observed around Head 10-15 and Layer 10-18.
* Lowest attention values (dark blue) are sparse, primarily appearing in the lower layers and edges of the head range.
**2. Math (Any)** (Top-Right)
* **Trend:** This heatmap exhibits a more chaotic and dispersed pattern of attention compared to "Math (Always)". High attention areas (red/yellow) are scattered throughout the grid, with no clear concentration in specific layers or heads.
* **Data Points (Approximate):**
* Attention values are more evenly distributed across the color scale.
* There are numerous isolated points of high attention.
* The heatmap appears to have a higher overall level of attention than "Math (Always)".
**3. Syntax (Always)** (Bottom-Left)
* **Trend:** This heatmap shows very sparse attention. The vast majority of the grid is dark blue, indicating very low attention values. There are only a few isolated points of green and yellow.
* **Data Points (Approximate):**
* Most head/layer combinations have attention values close to zero.
* A few heads (around Head 5-7) show slightly elevated attention in layers 10-12.
**4. Syntax (Any)** (Bottom-Right)
* **Trend:** Similar to "Math (Any)", this heatmap displays a dispersed pattern of attention, but with a generally lower overall intensity than "Math (Any)". There are several areas of moderate attention (green/yellow), but fewer areas of high attention (red).
* **Data Points (Approximate):**
* Attention values are more concentrated in the middle layers (approximately layers 8-18).
* The heatmap shows a diagonal pattern of moderate attention.
### Key Observations
* "Always" conditions (Math and Syntax) exhibit significantly lower overall attention compared to "Any" conditions.
* Math tasks generally show higher attention levels than Syntax tasks, regardless of the "Always" or "Any" condition.
* The "Syntax (Always)" heatmap is remarkably sparse, suggesting that attention heads are rarely consistently engaged for syntax tasks under the "Always" constraint.
* The "Math (Any)" heatmap is the most active, indicating a broad engagement of attention heads across layers for math tasks when attention is not constrained.
### Interpretation
These heatmaps likely represent the attention weights learned by a neural network model during training on mathematical and syntactical tasks. The "Always" condition likely refers to a scenario where attention is required for every step, while "Any" suggests attention can be selectively applied.
The data suggests that:
* **Math tasks benefit from more consistent attention.** The high attention levels in "Math (Always)" indicate that the model finds it useful to consistently attend to different parts of the input when solving math problems.
* **Syntax tasks are less reliant on consistent attention.** The sparsity of "Syntax (Always)" suggests that the model can effectively process syntax with less frequent attention.
* **Selective attention is crucial for both tasks.** The higher attention levels in the "Any" conditions demonstrate that the model can leverage attention to focus on the most relevant parts of the input when needed.
* **The model has learned different attention patterns for different tasks.** The distinct patterns observed in each heatmap suggest that the model has specialized attention mechanisms for math and syntax.
The observed differences in attention patterns could be due to the inherent complexity of the tasks, the training data, or the model architecture. Further analysis would be needed to determine the specific factors driving these patterns. The heatmap provides a visual representation of the model's internal workings, offering insights into how it processes and understands different types of information.