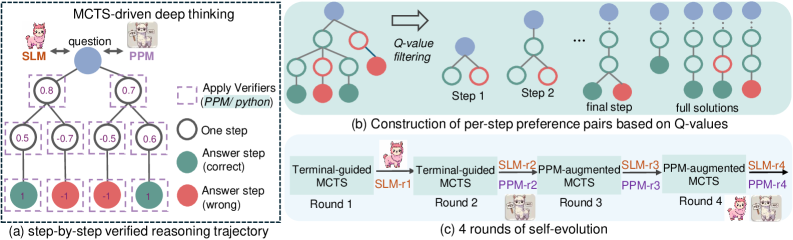
## Diagram: MCTS-Driven Deep Thinking Framework
### Overview
The image depicts a multi-stage technical framework for MCTS (Monte Carlo Tree Search)-driven deep thinking, visualized through three interconnected components:
1. **Step-by-Step Verified Reasoning Trajectory** (a)
2. **Per-Step Preference Pair Construction** (b)
3. **Self-Evolution Process** (c)
The framework emphasizes iterative reasoning, preference-based filtering, and self-improvement through multiple rounds of evolution.
---
### Components/Axes
#### (a) Step-by-Step Verified Reasoning Trajectory
- **Nodes**:
- **Question** (central blue node)
- **SLM** (left, pink icon)
- **PPM** (right, purple icon)
- **Answer Steps**:
- Correct (green circles)
- Wrong (red circles)
- **Intermediate Values**: Numerical scores (e.g., 0.8, 0.7, 0.5, -0.7, -0.5, 0.6, 1, -1)
- **Arrows**:
- Purple dashed lines (reasoning steps)
- Solid arrows (evolutionary flow)
- **Legend**:
- Green circles = Correct answer steps
- Red circles = Wrong answer steps
- Positioned on the right side of the diagram.
#### (b) Per-Step Preference Pair Construction
- **Nodes**:
- **Q-Value Filtering** (central blue node)
- **Step 1**, **Step 2**, **Final Step** (green/red circles)
- **Full Solutions** (blue nodes)
- **Arrows**:
- Rightward flow (→) indicating progression through steps.
- **Legend**:
- Blue circles = Q-value filtering
- Green circles = Correct steps
- Red circles = Incorrect steps
- Positioned on the right side of the diagram.
#### (c) Four Rounds of Self-Evolution
- **Rounds**:
- **Round 1**: Terminal-guided MCTS → SLM-r1 → Terminal-guided MCTS
- **Round 2**: SLM-r2 → PPM-augmented MCTS → SLM-r2
- **Round 3**: PPM-augmented MCTS → SLM-r3 → PPM-augmented MCTS
- **Round 4**: SLM-r4 → PPM-augmented MCTS → SLM-r4
- **Icons**:
- Pink (SLM) and purple (PPM) icons alternate across rounds.
- **Legend**:
- Orange = Terminal-guided MCTS
- Purple = PPM-augmented MCTS
- Positioned at the bottom of the diagram.
---
### Detailed Analysis
#### (a) Step-by-Step Verified Reasoning Trajectory
- **Flow**:
- The question (blue node) branches into SLM and PPM nodes.
- Intermediate values (e.g., 0.8, 0.7) represent confidence scores or evaluation metrics.
- Answer steps (green/red) indicate correctness, with green nodes having positive values (1) and red nodes negative (-1).
- **Key Values**:
- Highest positive value: 1 (correct answer step).
- Highest negative value: -1 (wrong answer step).
#### (b) Per-Step Preference Pair Construction
- **Q-Value Filtering**:
- Filters nodes based on Q-values (not explicitly quantified but implied by node pruning).
- Steps 1–2 show progressive refinement, culminating in "full solutions."
- **Trend**:
- Nodes reduce from multiple branches to a single path in later steps.
#### (c) Four Rounds of Self-Evolution
- **Iterative Process**:
- Each round alternates between SLM and PPM-augmented MCTS.
- "Terminal-guided" steps (orange) anchor the process, while "PPM-augmented" steps (purple) introduce external enhancements.
- **Trend**:
- Increasing complexity across rounds, with PPM augmentations becoming more frequent.
---
### Key Observations
1. **Color Consistency**:
- Green (correct) and red (wrong) nodes in (a) and (b) align with the legend.
- Orange (Terminal-guided) and purple (PPM-augmented) nodes in (c) match their legend labels.
2. **Flow Direction**:
- Arrows in (a) and (b) indicate left-to-right progression.
- (c) shows cyclical evolution across rounds.
3. **Numerical Values**:
- Values in (a) range from -1 to 1, suggesting a confidence or error metric.
- No explicit Q-values in (b), but node pruning implies threshold-based filtering.
---
### Interpretation
1. **Framework Purpose**:
- The diagram illustrates a self-improving reasoning system where MCTS is guided by SLM (Symbolic Language Model) and PPM (Probabilistic Prediction Model).
- Step verification (a) ensures correctness, while Q-value filtering (b) refines solutions iteratively.
2. **Self-Evolution Mechanism**:
- Rounds 1–4 demonstrate a hybrid approach: SLM handles symbolic reasoning, while PPM introduces probabilistic enhancements.
- Terminal-guided steps act as checkpoints, ensuring alignment with ground truth.
3. **Notable Patterns**:
- Negative values (-0.7, -0.5, -1) in (a) highlight error-prone steps, which are likely filtered out in (b).
- The final solutions in (b) represent optimized paths after multiple filtering stages.
4. **Technical Implications**:
- The framework balances symbolic reasoning (SLM) and probabilistic modeling (PPM) to enhance MCTS efficiency.
- Self-evolution suggests adaptive learning, where each round incorporates feedback from prior steps.
This diagram provides a blueprint for building robust, self-improving reasoning systems, emphasizing verification, filtering, and iterative refinement.