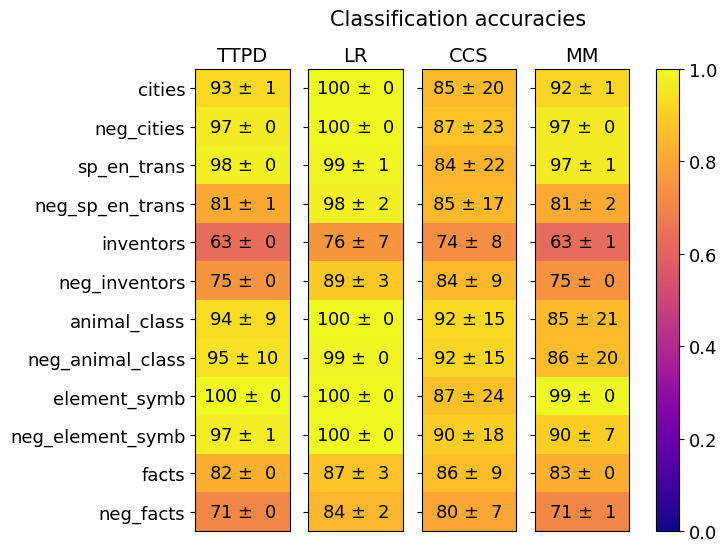
## Heatmap: Classification Accuracies
### Overview
This image presents a heatmap displaying classification accuracies for different categories across four models: TTPD, LR, CCS, and MM. The heatmap uses a color gradient from blue (low accuracy) to yellow (high accuracy) to represent the accuracy values. Each cell in the heatmap represents the accuracy of a specific model on a specific category, along with a standard deviation.
### Components/Axes
* **Title:** "Classification accuracies" (centered at the top)
* **Columns:** Represent the four models: TTPD, LR, CCS, MM (horizontally across the top).
* **Rows:** Represent the categories being classified: cities, neg\_cities, sp\_en\_trans, neg\_sp\_en\_trans, inventors, neg\_inventors, animal\_class, neg\_animal\_class, element\_symb, neg\_element\_symb, facts, neg\_facts (vertically along the left).
* **Color Scale:** A vertical color bar on the right indicates the accuracy range, from 0.0 (dark blue) to 1.0 (bright yellow).
* **Data Values:** Each cell contains a value in the format "X ± Y", representing the accuracy and standard deviation.
### Detailed Analysis
The heatmap displays the following accuracy values (approximated from the image):
**TTPD:**
* cities: 93 ± 1
* neg\_cities: 97 ± 0
* sp\_en\_trans: 98 ± 0
* neg\_sp\_en\_trans: 81 ± 1
* inventors: 63 ± 0
* neg\_inventors: 75 ± 0
* animal\_class: 94 ± 9
* neg\_animal\_class: 95 ± 10
* element\_symb: 100 ± 0
* neg\_element\_symb: 97 ± 1
* facts: 82 ± 0
* neg\_facts: 71 ± 0
**LR:**
* cities: 100 ± 0
* neg\_cities: 100 ± 0
* sp\_en\_trans: 99 ± 1
* neg\_sp\_en\_trans: 98 ± 2
* inventors: 76 ± 7
* neg\_inventors: 89 ± 3
* animal\_class: 100 ± 0
* neg\_animal\_class: 99 ± 0
* element\_symb: 100 ± 0
* neg\_element\_symb: 100 ± 0
* facts: 87 ± 3
* neg\_facts: 84 ± 2
**CCS:**
* cities: 85 ± 20
* neg\_cities: 87 ± 23
* sp\_en\_trans: 84 ± 22
* neg\_sp\_en\_trans: 85 ± 17
* inventors: 74 ± 8
* neg\_inventors: 84 ± 9
* animal\_class: 92 ± 15
* neg\_animal\_class: 92 ± 15
* element\_symb: 87 ± 24
* neg\_element\_symb: 90 ± 18
* facts: 86 ± 9
* neg\_facts: 80 ± 7
**MM:**
* cities: 92 ± 1
* neg\_cities: 97 ± 0
* sp\_en\_trans: 97 ± 1
* neg\_sp\_en\_trans: 81 ± 2
* inventors: 63 ± 1
* neg\_inventors: 75 ± 0
* animal\_class: 85 ± 21
* neg\_animal\_class: 86 ± 20
* element\_symb: 99 ± 0
* neg\_element\_symb: 90 ± 7
* facts: 83 ± 0
* neg\_facts: 71 ± 1
### Key Observations
* **LR consistently achieves the highest accuracies** across most categories, often reaching 100%.
* **TTPD and MM perform similarly** across many categories, with generally high accuracies.
* **CCS generally has the lowest accuracies**, with larger standard deviations in some cases (e.g., cities).
* **The "inventors" and "neg\_inventors" categories consistently show lower accuracies** across all models compared to other categories.
* **The "neg\_" categories generally have high accuracy** across all models.
* The standard deviations are relatively small for most categories, indicating consistent performance. However, "cities" for CCS has a large standard deviation (±20).
### Interpretation
This heatmap demonstrates the performance of four different classification models on a set of diverse categories. The LR model appears to be the most effective overall, achieving near-perfect accuracy on many tasks. The consistently lower performance on the "inventors" and "neg\_inventors" categories suggests that this particular classification task is more challenging for all models, potentially due to the complexity of the data or the ambiguity of the category itself. The high accuracy on "neg\_" categories suggests that the models are effective at identifying negative examples. The large standard deviation for CCS on "cities" indicates that the model's performance on this category is less consistent, and may be more sensitive to variations in the input data. The heatmap provides a clear visual comparison of the models' strengths and weaknesses, allowing for informed decisions about which model to use for specific classification tasks. The use of "neg\_" categories suggests a focus on robustness and the ability to correctly identify instances that *do not* belong to a given class.