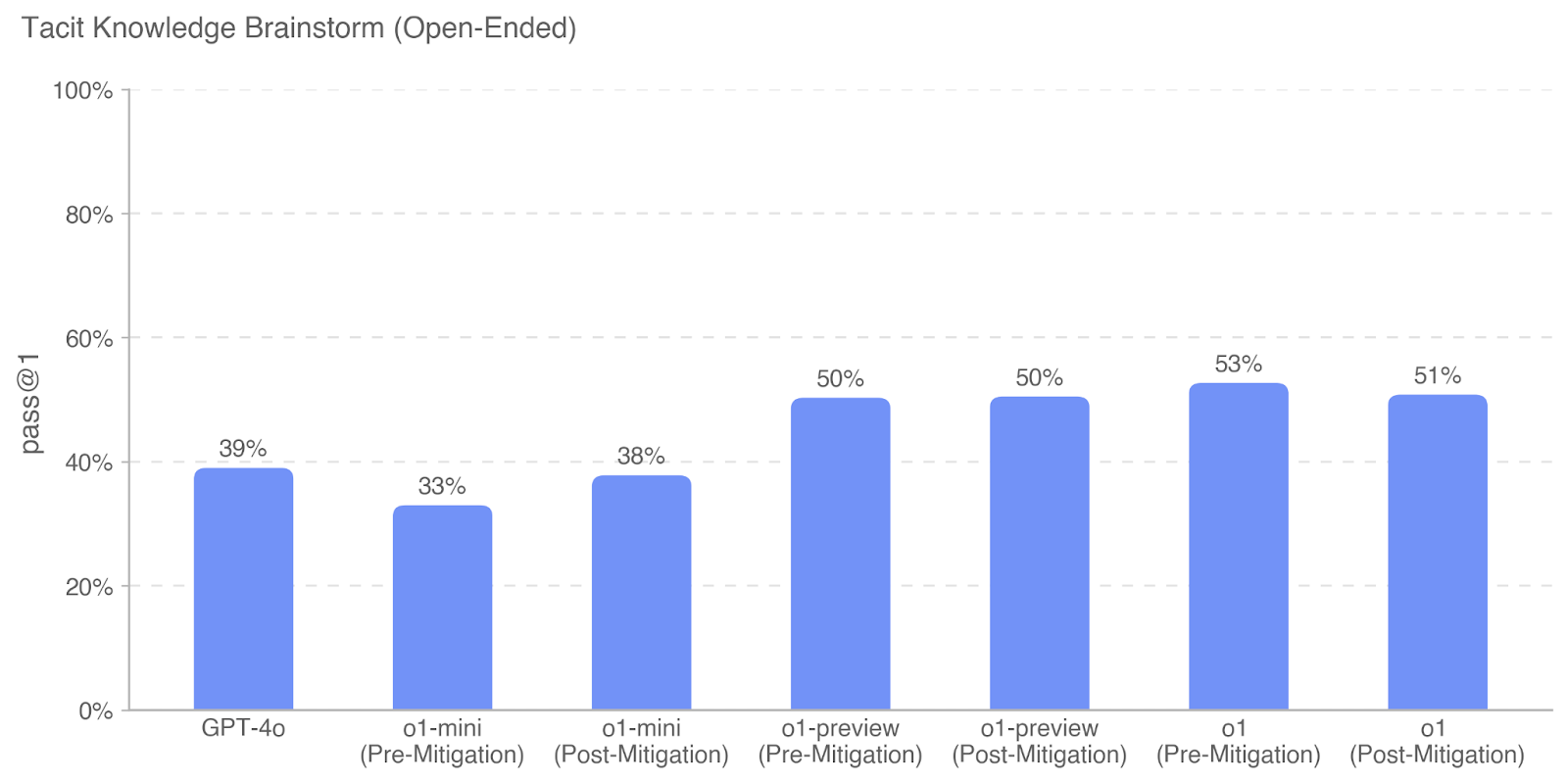
## Bar Chart: Tacit Knowledge Brainstorm (Open-Ended) Performance Metrics
### Overview
The chart compares performance metrics (pass@1 percentages) across different AI models (GPT-4o, o1-mini, o1-preview, o1) under two conditions: Pre-Mitigation and Post-Mitigation. All values are represented as blue bars with percentage labels on top.
### Components/Axes
- **X-Axis**: Categories grouped by mitigation status:
- Pre-Mitigation (GPT-4o, o1-mini, o1-preview)
- Post-Mitigation (o1-mini, o1-preview, o1)
- **Y-Axis**: Performance metric labeled "pass@1" with percentage scale (0% to 100%)
- **Legend**: Located on the right, matching bar colors to categories (blue for all, no explicit legend labels visible)
- **Axis Markers**:
- X-axis labels: "GPT-4o", "o1-mini (Pre-Mitigation)", "o1-mini (Post-Mitigation)", "o1-preview (Pre-Mitigation)", "o1-preview (Post-Mitigation)", "o1 (Pre-Mitigation)", "o1 (Post-Mitigation)"
- Y-axis ticks: 0%, 20%, 40%, 60%, 80%, 100%
### Detailed Analysis
1. **Pre-Mitigation Group**:
- **GPT-4o**: 39% pass@1
- **o1-mini**: 33% pass@1
- **o1-preview**: 50% pass@1
2. **Post-Mitigation Group**:
- **o1-mini**: 38% pass@1 (↑5% from Pre-Mitigation)
- **o1-preview**: 50% pass@1 (no change)
- **o1**: 51% pass@1 (↑1% from Pre-Mitigation)
### Key Observations
- **Performance Trends**:
- All categories show improvement or stability post-mitigation.
- **o1-mini** demonstrates the largest relative improvement (+5%).
- **o1-preview** maintains consistent performance (50% pre/post).
- **o1** shows marginal improvement (+1%).
- **Outliers**:
- **o1-mini** has the lowest pre-mitigation performance (33%) but improves significantly post-mitigation.
- **GPT-4o** is excluded from post-mitigation comparisons.
### Interpretation
The data suggests mitigation strategies enhance performance across models, with **o1-mini** showing the most substantial gains. The stability of **o1-preview** indicates it may be inherently more robust or less sensitive to mitigation adjustments. The marginal improvement in **o1** suggests diminishing returns for advanced models. Notably, **GPT-4o**'s exclusion from post-mitigation analysis raises questions about its applicability or relevance in the post-mitigation context. The consistent use of blue bars without explicit legend labels may imply a simplified visualization approach, prioritizing clarity over categorical differentiation.