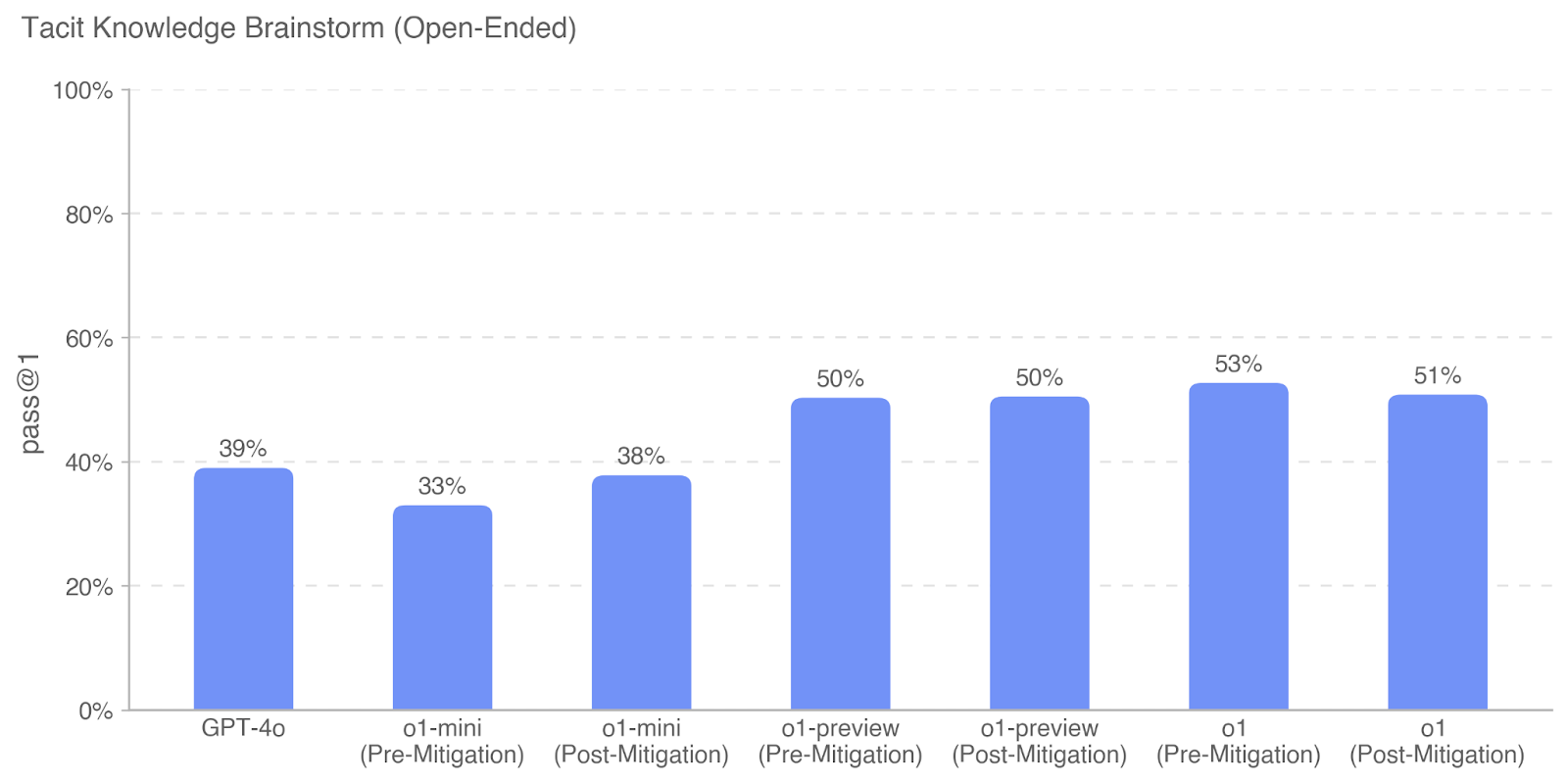
## Bar Chart: Tacit Knowledge Brainstorm (Open-Ended) Performance
### Overview
The image is a vertical bar chart titled "Tacit Knowledge Brainstorm (Open-Ended)". It displays the performance, measured by a "pass @1" metric, for several AI models or model variants. The chart compares a baseline model (GPT-4o) against variants of the "o1" model series, each shown in both "Pre-Mitigation" and "Post-Mitigation" states.
### Components/Axes
* **Chart Title:** "Tacit Knowledge Brainstorm (Open-Ended)" (located at the top-left).
* **Y-Axis:**
* **Label:** "pass @1" (rotated vertically on the left side).
* **Scale:** Linear scale from 0% to 100%.
* **Major Gridlines/Ticks:** 0%, 20%, 40%, 60%, 80%, 100% (dashed horizontal lines).
* **X-Axis:**
* **Categories (from left to right):**
1. GPT-4o
2. o1-mini (Pre-Mitigation)
3. o1-mini (Post-Mitigation)
4. o1-preview (Pre-Mitigation)
5. o1-preview (Post-Mitigation)
6. o1 (Pre-Mitigation)
7. o1 (Post-Mitigation)
* **Data Series:** A single series represented by solid blue bars. No legend is present as there is only one data type.
* **Data Labels:** The exact percentage value is displayed above each bar.
### Detailed Analysis
The chart presents the following specific data points:
| Model Variant | pass @1 |
| :--- | :--- |
| GPT-4o | 39% |
| o1-mini (Pre-Mitigation) | 33% |
| o1-mini (Post-Mitigation) | 38% |
| o1-preview (Pre-Mitigation) | 50% |
| o1-preview (Post-Mitigation) | 50% |
| o1 (Pre-Mitigation) | 53% |
| o1 (Post-Mitigation) | 51% |
**Visual Trend Verification:**
* The performance of the "o1-mini" series is lower than the baseline GPT-4o in its pre-mitigation state but improves slightly post-mitigation.
* The "o1-preview" series shows a significant jump in performance compared to both GPT-4o and o1-mini, holding steady at 50% before and after mitigation.
* The "o1" series demonstrates the highest performance on the chart, peaking at 53% pre-mitigation, with a slight decrease to 51% post-mitigation.
### Key Observations
* **Performance Hierarchy:** The "o1" model variants consistently outperform the "o1-mini" variants and the GPT-4o baseline. The "o1-preview" and "o1" models are in a higher performance tier (50%+).
* **Mitigation Impact:** The effect of "mitigation" is inconsistent across model variants.
* For **o1-mini**, mitigation correlates with a **+5 percentage point** increase (33% to 38%).
* For **o1-preview**, mitigation shows **no change** (50% to 50%).
* For **o1**, mitigation correlates with a **-2 percentage point** decrease (53% to 51%).
* **Highest Value:** The single highest recorded performance is 53% by **o1 (Pre-Mitigation)**.
* **Lowest Value:** The lowest recorded performance is 33% by **o1-mini (Pre-Mitigation)**.
### Interpretation
This chart likely evaluates the ability of different AI models to generate correct answers on the first attempt ("pass @1") for a task requiring "tacit knowledge" – practical, experiential knowledge that is difficult to codify. The "Open-Ended" qualifier suggests the task involves creative or non-prescriptive problem-solving.
The data suggests that the **o1 model series represents a substantial capability leap over GPT-4o** for this specific type of task, with the full "o1" model being the most capable. The "mitigation" process, which could refer to safety fine-tuning, alignment techniques, or other post-training interventions, has a **non-uniform effect on performance**. It appears to benefit the smaller "o1-mini" model, has a neutral effect on "o1-preview," and may cause a minor performance trade-off in the flagship "o1" model. This highlights a potential tension between capability and safety/alignment interventions that varies by model scale and version. The consistency of the "o1-preview" score is notable, suggesting its performance on this task is robust to the applied mitigation.