\n
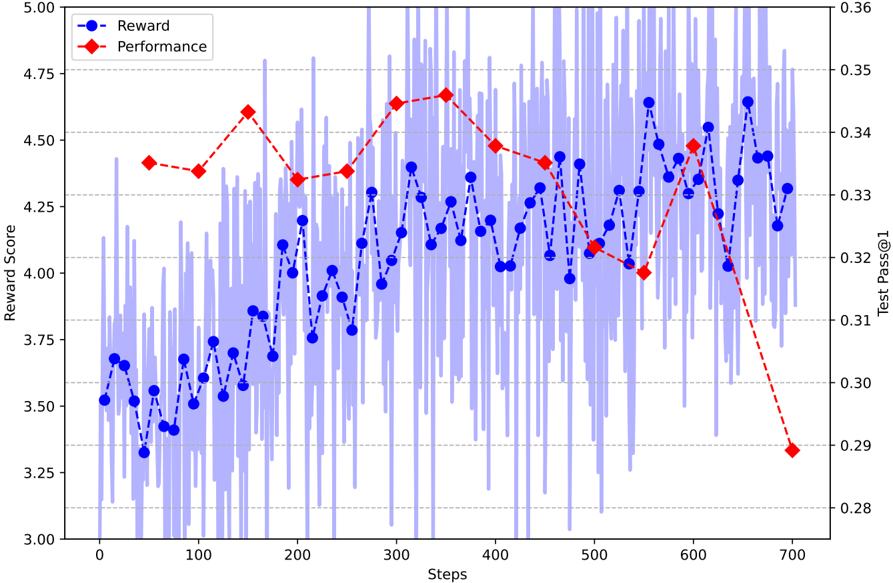
## Line Chart: Reward Score vs. Steps with Performance Overlay
### Overview
This image presents a line chart illustrating the relationship between 'Steps' and 'Reward Score', with an overlaid line representing 'Performance'. The chart displays the evolution of these metrics over approximately 700 steps. The 'Reward Score' is plotted on the primary y-axis (left), while 'Performance' is plotted on the secondary y-axis (right). A shaded region around the 'Reward Score' line indicates variability or standard deviation.
### Components/Axes
* **X-axis:** 'Steps', ranging from 0 to 700, with increments of approximately 50.
* **Primary Y-axis (left):** 'Reward Score', ranging from 3.00 to 5.00, with increments of approximately 0.25.
* **Secondary Y-axis (right):** 'Test Pass@1' (Performance), ranging from 0.28 to 0.36, with increments of approximately 0.02.
* **Legend:** Located in the top-left corner, identifying two data series:
* 'Reward' (Blue line with circle markers)
* 'Performance' (Red line with diamond markers)
* **Shaded Region:** A light blue shaded area surrounds the 'Reward' line, representing the variability around the mean reward score.
* **Gridlines:** Horizontal gridlines are present to aid in reading values on both y-axes.
### Detailed Analysis
**Reward (Blue Line):**
The 'Reward' line exhibits a generally upward trend from step 0 to approximately step 300, followed by fluctuations and a slight downward trend between steps 300 and 500. From step 500 onwards, the line shows a significant increase, followed by a sharp decline towards step 700.
* Step 0: Reward Score ≈ 3.40
* Step 50: Reward Score ≈ 3.55
* Step 100: Reward Score ≈ 3.70
* Step 150: Reward Score ≈ 3.85
* Step 200: Reward Score ≈ 4.00
* Step 250: Reward Score ≈ 4.15
* Step 300: Reward Score ≈ 4.25
* Step 350: Reward Score ≈ 4.20
* Step 400: Reward Score ≈ 4.10
* Step 450: Reward Score ≈ 4.05
* Step 500: Reward Score ≈ 4.10
* Step 550: Reward Score ≈ 4.45
* Step 600: Reward Score ≈ 4.50
* Step 650: Reward Score ≈ 4.25
* Step 700: Reward Score ≈ 3.90
The shaded region around the 'Reward' line indicates a significant degree of variability, with the reward score fluctuating considerably around the mean value at most steps.
**Performance (Red Line):**
The 'Performance' line initially shows an increase from step 0 to approximately step 300, reaching a peak around step 300-350. After this peak, the line generally declines, with a particularly steep drop between steps 600 and 700.
* Step 0: Performance ≈ 0.31
* Step 50: Performance ≈ 0.32
* Step 100: Performance ≈ 0.33
* Step 150: Performance ≈ 0.34
* Step 200: Performance ≈ 0.35
* Step 250: Performance ≈ 0.35
* Step 300: Performance ≈ 0.35
* Step 350: Performance ≈ 0.35
* Step 400: Performance ≈ 0.34
* Step 450: Performance ≈ 0.33
* Step 500: Performance ≈ 0.32
* Step 550: Performance ≈ 0.31
* Step 600: Performance ≈ 0.30
* Step 650: Performance ≈ 0.29
* Step 700: Performance ≈ 0.28
### Key Observations
* The 'Reward' and 'Performance' lines initially show a positive correlation, increasing together until around step 300.
* After step 300, the 'Performance' line begins to decline while the 'Reward' line continues to fluctuate.
* The sharp decline in 'Performance' between steps 600 and 700 is particularly noticeable and does not have a corresponding sharp decline in 'Reward' initially, suggesting a decoupling of the two metrics.
* The 'Reward' line exhibits high variability, as indicated by the large shaded region.
### Interpretation
The chart suggests a learning process where both reward and performance initially improve with increasing steps. However, around step 300, the relationship between reward and performance begins to diverge. This could indicate that the agent is achieving higher rewards through strategies that do not necessarily translate to improved performance on the 'Test Pass@1' metric. The steep decline in performance towards the end of the training process suggests a potential overfitting or instability in the learned policy. The high variability in the reward score indicates that the learning process is stochastic and subject to significant fluctuations. The decoupling of reward and performance at the end of the training suggests that maximizing reward may not be directly aligned with achieving optimal performance on the test set. Further investigation is needed to understand the reasons behind this divergence and to improve the stability and generalization ability of the learned policy.