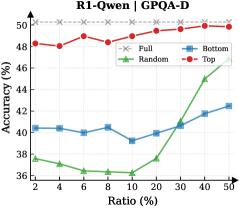
## Chart: Accuracy vs Ratio for R1-Qwen | GPQA-D
### Overview
The image is a line chart comparing the accuracy (%) of different models (Full, Random, Bottom, Top) against the ratio (%) on the R1-Qwen | GPQA-D dataset. The x-axis represents the ratio (%), and the y-axis represents the accuracy (%).
### Components/Axes
* **Title:** R1-Qwen | GPQA-D
* **X-axis:** Ratio (%) with markers at 2, 4, 6, 8, 10, 20, 30, 40, 50
* **Y-axis:** Accuracy (%) with markers at 36, 38, 40, 42, 44, 46, 48, 50
* **Legend:** Located in the top-right corner.
* Full (Gray dashed line with x markers)
* Random (Green line with triangle markers)
* Bottom (Blue line with square markers)
* Top (Red line with circle markers)
### Detailed Analysis
* **Full (Gray dashed line with x markers):** The accuracy remains constant at approximately 50% across all ratios.
* Ratio 2%: 50.2%
* Ratio 50%: 50.2%
* **Random (Green line with triangle markers):** The accuracy decreases from 37.5% to 36% between ratios 2% and 8%, then increases sharply from 36% to 46.5% between ratios 8% and 50%.
* Ratio 2%: 37.5%
* Ratio 8%: 36%
* Ratio 50%: 46.5%
* **Bottom (Blue line with square markers):** The accuracy fluctuates between 40% and 42% from ratios 2% to 40%, then increases slightly to 42% at ratio 50%.
* Ratio 2%: 40.5%
* Ratio 8%: 39.2%
* Ratio 40%: 41.8%
* Ratio 50%: 42%
* **Top (Red line with circle markers):** The accuracy fluctuates between 48% and 50% across all ratios.
* Ratio 2%: 48.3%
* Ratio 6%: 49%
* Ratio 50%: 49.8%
### Key Observations
* The "Full" model consistently achieves the highest accuracy, remaining stable at approximately 50% across all ratios.
* The "Random" model shows a significant increase in accuracy as the ratio increases, starting low and rising sharply after a ratio of 10%.
* The "Bottom" model's accuracy remains relatively stable, with minor fluctuations around 40-42%.
* The "Top" model's accuracy is consistently high, fluctuating slightly around 48-50%.
### Interpretation
The chart compares the performance of different models (Full, Random, Bottom, Top) in terms of accuracy as the ratio changes. The "Full" model represents a complete or ideal model, achieving consistently high accuracy. The "Random" model's performance improves significantly with increasing ratio, suggesting that it benefits from more data or a larger sample size. The "Bottom" model's stable but lower accuracy indicates a consistent but less effective approach. The "Top" model performs well, but not as consistently as the "Full" model. The data suggests that the "Full" model is the most reliable, while the "Random" model's performance is highly dependent on the ratio. The "Bottom" model provides a baseline, and the "Top" model offers a good but not optimal solution.