# Technical Document Analysis: Retrieval-Augmented Generation (RAG) vs Self-reflective Retrieval-Augmented Generation (Self-RAG)
## Overview
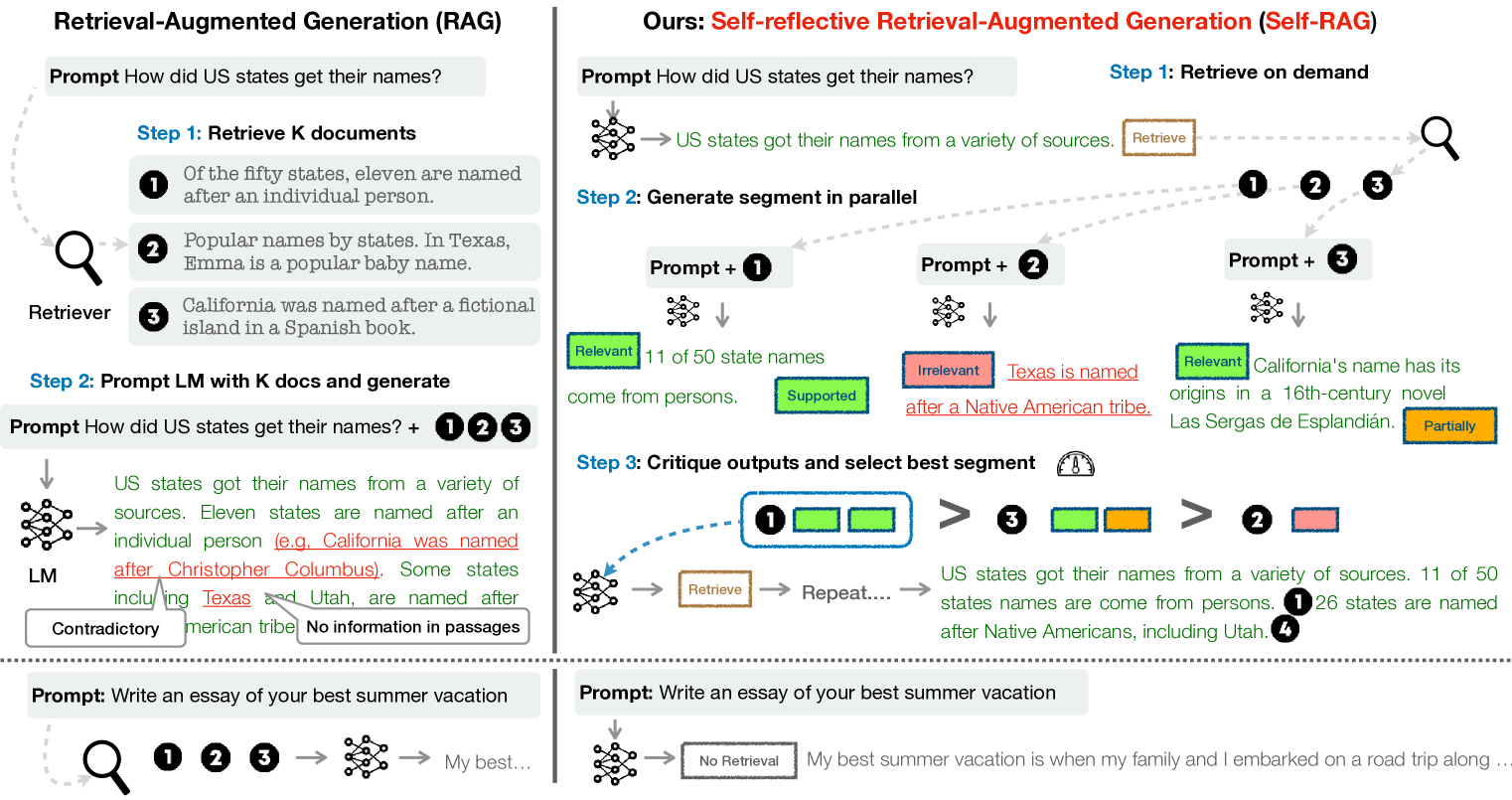
The image compares two generative AI frameworks: **RAG** (Retrieval-Augmented Generation) and **Self-RAG** (Self-reflective Retrieval-Augmented Generation). It illustrates workflows, outputs, and evaluation mechanisms for each method.
---
## **RAG Framework**
### Step 1: Retrieve K Documents
- **Retriever** extracts documents based on a prompt.
- **Example Documents**:
1. "Of the fifty states, eleven are named after an individual person."
2. "In Texas, Emma is a popular baby name."
3. "California was named after a fictional island in a Spanish book."
### Step 2: Prompt LM with K Docs and Generate
- **Prompt**: "How did US states get their names?"
- **LM Output**:
- "US states got their names from a variety of sources. Eleven states are named after an individual person (e.g., California was named after Christopher Columbus). Some states, including Texas and Utah, are named after American tribes."
- **Annotations**:
- **Contradictory**: "Texas and Utah" (conflict with document 3, which states California was named after a fictional island).
- **No information in passages**: Missing context about Native American tribes.
### Step 3: Essay Generation
- **Prompt**: "Write an essay of your best summer vacation."
- **LM Output**: "My best..." (incomplete response).
---
## **Self-RAG Framework**
### Step 1: Retrieve on Demand
- **Retrieve** button triggers document retrieval.
- **Example Output**: "US states got their names from a variety of sources."
### Step 2: Generate Segments in Parallel
- **Parallel Prompts**:
1. **Prompt + 1**: "US states got their names from a variety of sources. Eleven of 50 state names come from persons."
- **Relevance**: ✅ Relevant.
2. **Prompt + 2**: "Texas is named after a Native American tribe."
- **Relevance**: ❌ Irrelevant (contradicts document 3).
3. **Prompt + 3**: "California's name has its origins in a 16th-century novel, Las Sergas de Esplandían."
- **Relevance**: ✅ Relevant (partially supported by document 3).
### Step 3: Critique Outputs and Select Best Segment
- **Evaluation Process**:
- **Gauge** ranks segments by relevance.
- **Selection**:
- **Segment 1**: ✅ Relevant (11 states named after persons).
- **Segment 3**: ✅ Relevant (California's origin).
- **Segment 2**: ❌ Irrelevant (Texas/Utah claim).
- **Final Output**:
- "US states got their names from a variety of sources. 11 of 50 states names are come from persons. 26 states are named after Native Americans, including Utah."
### Step 4: Essay Generation
- **Prompt**: "Write an essay of your best summer vacation."
- **LM Output**: "My best summer vacation is when my family and I embarked on a road trip along..." (complete response).
---
## Key Differences
| **Aspect** | **RAG** | **Self-RAG** |
|--------------------------|----------------------------------|---------------------------------------|
| **Retrieval** | Fixed K documents | On-demand retrieval |
| **Generation** | Single LM output | Parallel segment generation |
| **Evaluation** | No explicit critique | Relevance scoring and selection |
| **Output Quality** | Contradictory/incomplete | Refined, contextually accurate |
---
## Critical Observations
1. **RAG Limitations**:
- Fixed document retrieval may lead to contradictions (e.g., Texas/Utah vs. California's origin).
- LM outputs lack coherence in essay generation.
2. **Self-RAG Advantages**:
- Dynamic retrieval adapts to prompts.
- Parallel generation enables cross-verification of segments.
- Relevance scoring improves output accuracy.
3. **Technical Components**:
- **RAG**: Linear workflow (Retrieve → Generate).
- **Self-RAG**: Iterative workflow (Retrieve → Generate in Parallel → Critique → Select Best Segment).
---
## Diagram Components
### RAG Diagram
- **Nodes**:
- Prompt → Retriever → K Documents → LM Output.
- **Annotations**:
- Contradictions and missing information highlighted.
### Self-RAG Diagram
- **Nodes**:
- Prompt → Retrieve → Parallel Segments (1, 2, 3) → Critique → Final Output.
- **Color Coding**:
- Green: Relevant.
- Red: Irrelevant.
- Yellow: Partially supported.
---
## Conclusion
Self-RAG enhances RAG by introducing **dynamic retrieval**, **parallel generation**, and **explicit critique mechanisms**, resulting in more accurate and contextually coherent outputs.