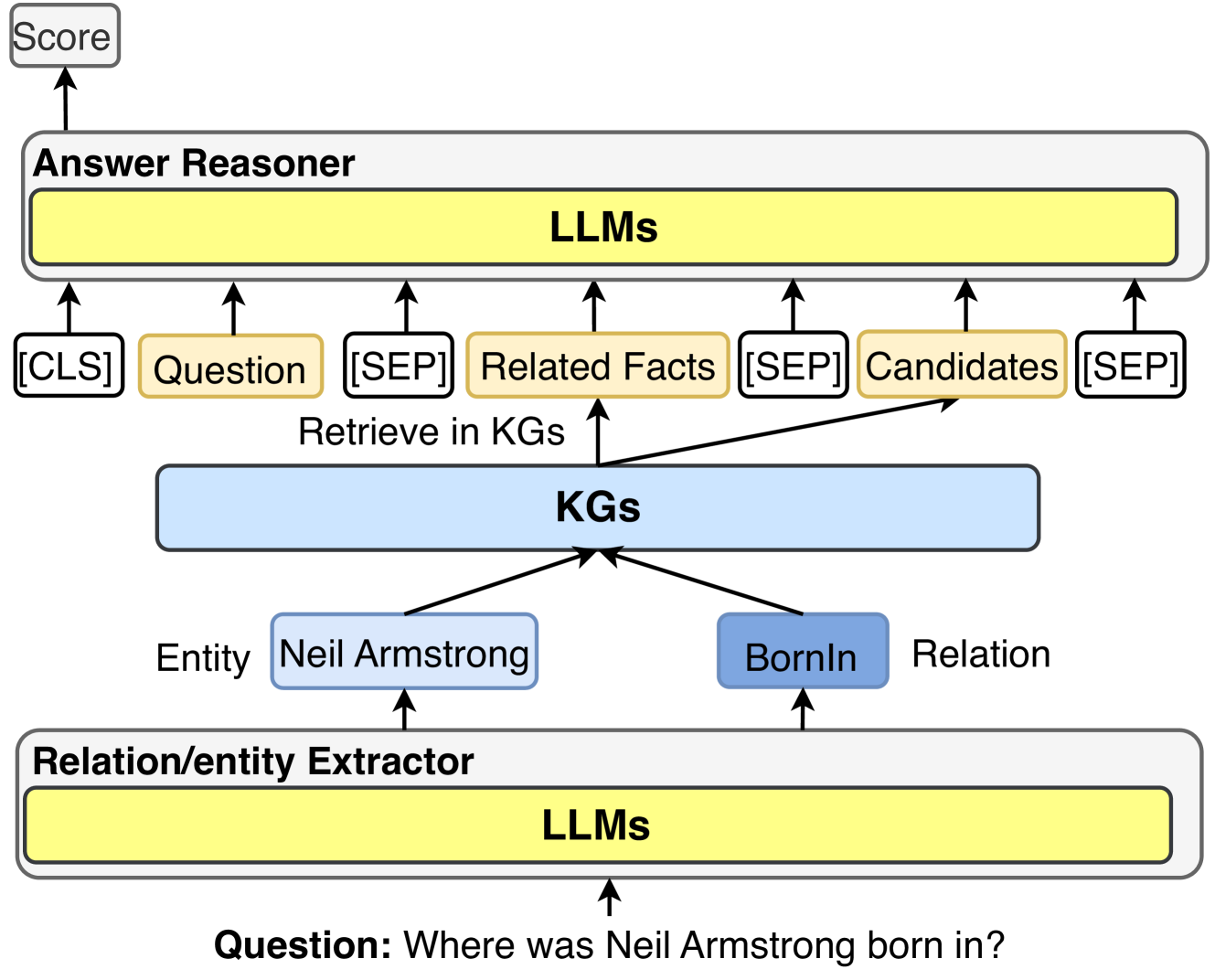
## Diagram: Knowledge Graph Question Answering System
### Overview
The image depicts a system for answering questions using knowledge graphs (KGs) and large language models (LLMs). The system takes a question as input, extracts relevant entities and relations, retrieves information from KGs, reasons over the retrieved information using LLMs, and outputs a score representing the confidence in the answer.
### Components/Axes
* **Top-Left:** "Score" - Indicates the output of the system.
* **Top:** "Answer Reasoner" - The module responsible for reasoning over the retrieved information.
* "LLMs" - A yellow box representing the Large Language Models used for reasoning.
* "[CLS]" - A grey box.
* "Question" - A yellow box.
* "[SEP]" - A grey box.
* "Related Facts" - A yellow box.
* "[SEP]" - A grey box.
* "Candidates" - A yellow box.
* "[SEP]" - A grey box.
* **Center:** "Retrieve in KGs" - Text indicating the retrieval of information from Knowledge Graphs.
* "KGs" - A light blue box representing the Knowledge Graphs.
* **Bottom-Center:**
* "Entity Neil Armstrong" - A light blue box representing the entity extracted from the question.
* "BornIn Relation" - A light blue box representing the relation extracted from the question.
* **Bottom:** "Relation/entity Extractor" - The module responsible for extracting entities and relations from the input question.
* "LLMs" - A yellow box representing the Large Language Models used for extraction.
* **Bottom:** "Question: Where was Neil Armstrong born in?" - The input question.
### Detailed Analysis
The diagram illustrates the flow of information in a knowledge graph question answering system.
1. **Input Question:** The system starts with the question "Where was Neil Armstrong born in?".
2. **Relation/entity Extractor:** The "Relation/entity Extractor" module, powered by LLMs, extracts the entity "Neil Armstrong" and the relation "BornIn Relation" from the question.
3. **KGs Retrieval:** The extracted entity and relation are used to retrieve relevant information from the "KGs" (Knowledge Graphs).
4. **Answer Reasoner:** The retrieved information, along with the original question, is fed into the "Answer Reasoner" module. This module, powered by LLMs, reasons over the information to generate candidate answers. The input to the LLMs includes "[CLS]", "Question", "[SEP]", "Related Facts", "[SEP]", "Candidates", "[SEP]".
5. **Output Score:** The system outputs a "Score" representing the confidence in the answer.
### Key Observations
* The system uses LLMs for both entity/relation extraction and answer reasoning.
* The KGs serve as the source of factual knowledge.
* The "[CLS]" and "[SEP]" tokens are used to structure the input to the LLMs.
### Interpretation
The diagram illustrates a common architecture for knowledge graph question answering systems. The system leverages the power of LLMs to understand the question, extract relevant information from KGs, and reason over the retrieved information to generate answers. The use of "[CLS]" and "[SEP]" tokens suggests that the LLMs are likely using a transformer-based architecture. The system aims to provide accurate answers to questions by combining the strengths of LLMs and KGs.