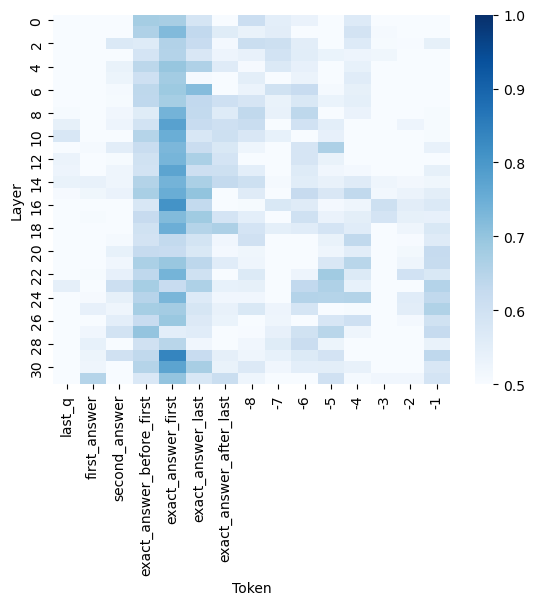
## Heatmap: Attention Weights Across Transformer Layers and Tokens
### Overview
The image is a heatmap visualizing attention weights across transformer model layers and tokens. Darker blue shades represent higher attention values (closer to 1.0), while lighter shades indicate lower values (closer to 0.5). The chart spans 30 layers (vertical axis) and 31 tokens (horizontal axis), with a color scale on the right.
### Components/Axes
- **Vertical Axis (Layer)**:
- Labels: `last_q`, `first_answer`, `second_answer`, `exact_answer_before_first`, `exact_answer_first`, `exact_answer_last`, `exact_answer_after_last`.
- Numerical indices: 1 to 30 (bottom to top).
- **Horizontal Axis (Token)**:
- Labels: `-1`, `1`, `2`, `3`, `4`, `5`, `6`, `7`, `8`, `9`, `10`, `11`, `12`, `13`, `14`, `15`, `16`, `17`, `18`, `19`, `20`, `21`, `22`, `23`, `24`, `25`, `26`, `27`, `28`, `29`, `30`.
- **Legend**:
- Positioned on the right, with a gradient from light gray (0.5) to dark blue (1.0).
### Detailed Analysis
- **Layer Categories**:
- `last_q` (Layer 30): High attention at token `-1` (dark blue).
- `first_answer` (Layer 29): High attention at token `12` (dark blue).
- `second_answer` (Layer 28): High attention at token `14` (dark blue).
- `exact_answer_before_first` (Layer 27): High attention at token `12` (dark blue).
- `exact_answer_first` (Layer 26): High attention at token `14` (dark blue).
- `exact_answer_last` (Layer 25): High attention at token `12` (dark blue).
- `exact_answer_after_last` (Layer 24): High attention at token `14` (dark blue).
- **Token Categories**:
- Tokens `12` and `14` consistently show the highest attention values across layers 24–29.
- Token `-1` (first token) has high attention only in layer 30 (`last_q`).
- Tokens `1–11` and `15–30` show lower attention values (lighter shades).
### Key Observations
1. **Central Focus**: Layers 24–29 (exact answer-related layers) exhibit concentrated attention on tokens `12` and `14`, suggesting these tokens are critical for answer extraction.
2. **Edge Layers**: Layers 1–23 and 30 show sparse high-attention regions, with layer 30 (`last_q`) uniquely focusing on token `-1`.
3. **Color Consistency**: Dark blue regions align with the legend’s highest values (0.9–1.0), confirming the scale’s accuracy.
### Interpretation
The heatmap reveals that transformer layers 24–29 (associated with answer extraction) prioritize tokens `12` and `14`, likely corresponding to key words or phrases in the input sequence. The unique focus of layer 30 on token `-1` (often a special token like `[CLS]` or `[SEP]`) suggests it may encode global context. The sparse attention in earlier layers implies hierarchical processing, with later layers refining focus to critical tokens. This pattern aligns with typical transformer behavior, where deeper layers capture semantic relationships.