TECHNICAL ASSET FINGERPRINT
44526bbe19fc3dafc3de44a6
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemini-2.0-flash VERSION 1
RUNTIME: nugit/gemini/gemini-2.0-flash
INTEL_VERIFIED
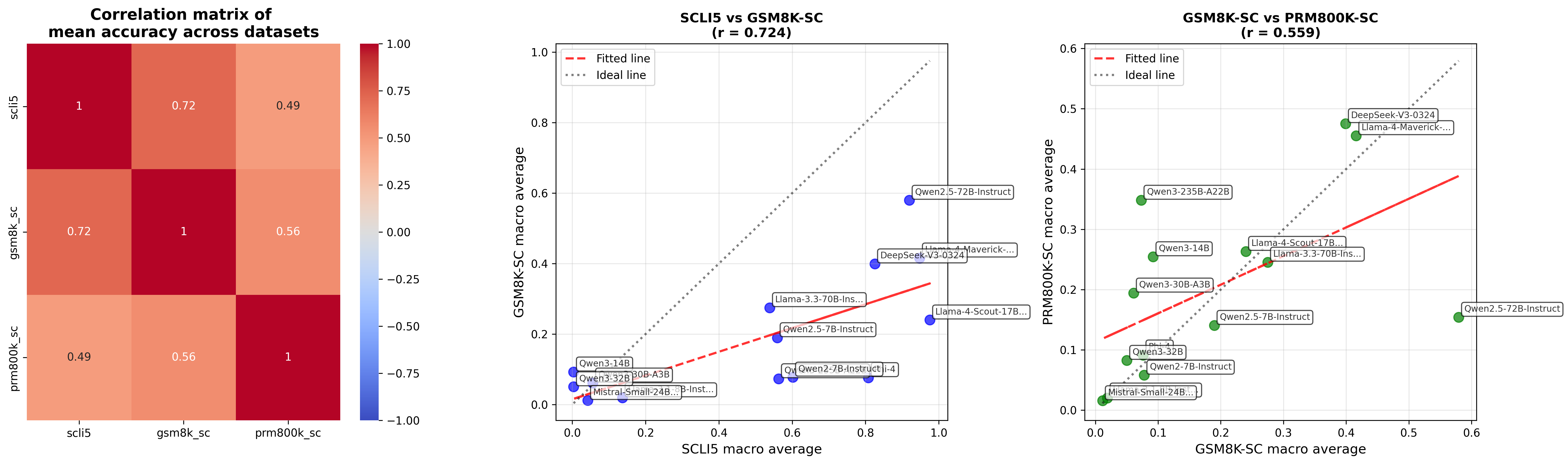
## Chart Type: Multi-Panel Data Analysis
### Overview
The image presents a multi-panel data analysis consisting of a correlation matrix and two scatter plots. The correlation matrix displays the mean accuracy correlations between three datasets: scli5, gsm8k_sc, and prm800k_sc. The scatter plots compare the macro averages of these datasets, with fitted lines and ideal lines overlaid to visualize the relationships.
### Components/Axes
**Panel 1: Correlation Matrix**
* **Title:** Correlation matrix of mean accuracy across datasets
* **X-axis Labels:** scli5, gsm8k_sc, prm800k_sc
* **Y-axis Labels:** scli5, gsm8k_sc, prm800k_sc
* **Color Scale:** Ranges from blue (-1.00) to red (1.00), with white representing 0.00.
* **Values:** Displayed within each cell of the matrix.
**Panel 2: Scatter Plot 1**
* **Title:** SCLI5 vs GSM8K-SC (r = 0.724)
* **X-axis Label:** SCLI5 macro average
* Scale: 0.0 to 1.0, incrementing by 0.2
* **Y-axis Label:** GSM8K-SC macro average
* Scale: 0.0 to 1.0, incrementing by 0.2
* **Data Points:** Blue circles, each labeled with a model name.
* **Fitted Line:** Red dashed line.
* **Ideal Line:** Gray dotted line.
* **Legend (Top-Left):**
* Fitted line: Red dashed line
* Ideal line: Gray dotted line
**Panel 3: Scatter Plot 2**
* **Title:** GSM8K-SC vs PRM800K-SC (r = 0.559)
* **X-axis Label:** GSM8K-SC macro average
* Scale: 0.0 to 0.6, incrementing by 0.1
* **Y-axis Label:** PRM800K-SC macro average
* Scale: 0.0 to 0.6, incrementing by 0.1
* **Data Points:** Green circles, each labeled with a model name.
* **Fitted Line:** Red dashed line.
* **Ideal Line:** Gray dotted line.
* **Legend (Top-Left):**
* Fitted line: Red dashed line
* Ideal line: Gray dotted line
### Detailed Analysis
**Panel 1: Correlation Matrix**
| | scli5 | gsm8k_sc | prm800k_sc |
| :-------- | :---- | :------- | :---------- |
| **scli5** | 1 | 0.72 | 0.49 |
| **gsm8k_sc** | 0.72 | 1 | 0.56 |
| **prm800k_sc**| 0.49 | 0.56 | 1 |
* All diagonal values are 1, indicating perfect correlation of a dataset with itself.
* scli5 and gsm8k_sc have a strong positive correlation of 0.72.
* scli5 and prm800k_sc have a moderate positive correlation of 0.49.
* gsm8k_sc and prm800k_sc have a moderate positive correlation of 0.56.
**Panel 2: Scatter Plot 1 (SCLI5 vs GSM8K-SC)**
* The fitted line (red dashed) shows a positive correlation between SCLI5 and GSM8K-SC macro averages.
* The ideal line (gray dotted) represents a 1:1 correlation.
* Data points (blue) are scattered around the fitted line, indicating some variance.
* **Llama-3.3-70B-Ins...**: Approximately (0.1, 0.1)
* **Qwen3-32B**: Approximately (0.1, 0.1)
* **Qwen3-30B-A3B**: Approximately (0.2, 0.1)
* **Mistral-Small-24B...**: Approximately (0.2, 0.0)
* **Qwen2-7B-Instruct i-4**: Approximately (0.5, 0.1)
* **Llama-4-Scout-17B...**: Approximately (0.6, 0.2)
* **DeepSeek-V3-0324**: Approximately (0.9, 0.4)
* **Llama-4-Maverick-...**: Approximately (0.9, 0.4)
* **Qwen2.5-72B-Instruct**: Approximately (1.0, 0.6)
* **Qwen2.5-7B-Instruct**: Approximately (0.6, 0.2)
**Panel 3: Scatter Plot 2 (GSM8K-SC vs PRM800K-SC)**
* The fitted line (red dashed) shows a positive correlation between GSM8K-SC and PRM800K-SC macro averages.
* The ideal line (gray dotted) represents a 1:1 correlation.
* Data points (green) are scattered around the fitted line, indicating some variance.
* **Mistral-Small-24B...**: Approximately (0.0, 0.0)
* **Qwen2-7B-Instruct**: Approximately (0.1, 0.0)
* **Qwen3-32B**: Approximately (0.1, 0.1)
* **Qwen3-30B-A3B**: Approximately (0.1, 0.2)
* **Qwen3-14B**: Approximately (0.2, 0.25)
* **Qwen3-235B-A22B**: Approximately (0.2, 0.35)
* **Llama-4-Scout-17B...**: Approximately (0.3, 0.25)
* **Llama-3.3-70B-Ins...**: Approximately (0.3, 0.25)
* **DeepSeek-V3-0324**: Approximately (0.1, 0.5)
* **Llama-4-Maverick-...**: Approximately (0.1, 0.5)
* **Qwen2.5-7B-Instruct**: Approximately (0.6, 0.2)
### Key Observations
* The correlation matrix indicates a strong relationship between scli5 and gsm8k_sc datasets.
* The scatter plots show positive correlations between the datasets, but with noticeable variance around the fitted lines.
* The 'r' values (0.724 and 0.559) indicate the strength of the linear correlation, with SCLI5 vs GSM8K-SC having a stronger correlation than GSM8K-SC vs PRM800K-SC.
* The data points in the scatter plots represent different models, and their positions indicate their relative performance on the respective datasets.
### Interpretation
The data suggests that while there is a positive correlation in mean accuracy across the datasets, the relationships are not perfectly linear. The correlation matrix confirms the inter-relatedness of the datasets, while the scatter plots provide a more granular view of model performance across different dataset pairings. The variance around the fitted lines in the scatter plots indicates that model performance is not consistent across all datasets, and some models may perform better on certain datasets than others. The 'r' values quantify the strength of these relationships, with a higher 'r' value indicating a stronger linear association.
DECODING INTELLIGENCE...
EXPERT: nemotron-free VERSION 1
RUNTIME: free/nvidia/nemotron-nano-12b-v2-vl:free
INTEL_VERIFIED
## Heatmap: Correlation matrix of mean accuracy across datasets
### Overview
A 3x3 correlation matrix visualizing relationships between three datasets: scli5, gsm8k_sc, and prm800k_sc. Values range from -1 to 1, with darker red indicating stronger positive correlation.
### Components/Axes
- **Rows/Columns**:
- Top row: scli5
- Middle row: gsm8k_sc
- Bottom row: prm800k_sc
- **Color Scale**:
- Blue (-1.0) to Red (+1.0)
- White (0.0) as midpoint
- **Values**:
- Diagonal: All 1.0 (perfect self-correlation)
- Off-diagonal:
- scli5-gsm8k_sc: 0.72
- scli5-prm800k_sc: 0.49
- gsm8k_sc-prm800k_sc: 0.56
### Detailed Analysis
- **scli5**:
- Strongest correlation with gsm8k_sc (0.72)
- Moderate correlation with prm800k_sc (0.49)
- **gsm8k_sc**:
- Moderate correlation with prm800k_sc (0.56)
- **prm800k_sc**:
- Weakest overall correlation (0.49 with scli5)
### Key Observations
- All datasets show positive correlations
- scli5 and gsm8k_sc share the strongest relationship
- prm800k_sc demonstrates weaker but still positive relationships
### Interpretation
The matrix reveals that scli5 and gsm8k_sc are most closely related in terms of mean accuracy performance across datasets. prm800k_sc shows more divergent behavior, suggesting different underlying characteristics or performance patterns compared to the other two datasets.
---
## Scatter Plot: SCLI5 vs GSM8K-SC (r = 0.724)
### Overview
Scatter plot comparing SCLI5 and GSM8K-SC macro averages with fitted and ideal trend lines. Points labeled with model names.
### Components/Axes
- **X-axis**: SCLI5 macro average (0.0-1.0)
- **Y-axis**: GSM8K-SC macro average (0.0-1.0)
- **Legend**:
- Dashed red: Fitted line
- Dotted gray: Ideal line (y=x)
### Detailed Analysis
- **Trend**:
- Fitted line (r=0.724) shows strong positive correlation
- Points generally cluster near the ideal line
- **Data Points**:
- **Bottom-left cluster** (0.0-0.2 SCLI5, 0.0-0.2 GSM8K):
- Mistral-Small-24B-Instruct-v1.0
- Qwen3-32B
- Qwen3-30B-A3B
- **Middle cluster** (0.3-0.6 SCLI5, 0.2-0.4 GSM8K):
- Qwen2.5-7B-Instruct
- Qwen2.5-7B-Instruct-i4
- Qwen3-14B
- **Top-right cluster** (0.7-1.0 SCLI5, 0.4-0.8 GSM8K):
- Qwen2.5-72B-Instruct
- DeepSeek-V3-0324
- Llama-3-70B-Instruct-v1.0
### Key Observations
- High-performing models (top-right) show strong alignment between SCLI5 and GSM8K-SC
- Lower-performing models cluster in the bottom-left
- Fitted line closely follows the ideal line, indicating linear relationship
### Interpretation
The strong correlation (r=0.724) suggests that performance on SCLI5 strongly predicts performance on GSM8K-SC. The clustering of models indicates distinct performance tiers, with high-performing models showing consistent excellence across both benchmarks.
---
## Scatter Plot: GSM8K-SC vs PRM800K-SC (r = 0.559)
### Overview
Scatter plot comparing GSM8K-SC and PRM800K-SC macro averages with fitted and ideal trend lines. Points labeled with model names.
### Components/Axes
- **X-axis**: GSM8K-SC macro average (0.0-0.6)
- **Y-axis**: PRM800K-SC macro average (0.0-0.6)
- **Legend**:
- Dashed red: Fitted line
- Dotted gray: Ideal line (y=x)
### Detailed Analysis
- **Trend**:
- Fitted line (r=0.559) shows moderate positive correlation
- Points show more dispersion than previous plot
- **Data Points**:
- **Bottom-left cluster** (0.0-0.2 GSM8K, 0.0-0.2 PRM800K):
- Mistral-Small-24B-Instruct-v1.0
- Qwen3-32B
- Qwen2.5-7B-Instruct
- **Middle cluster** (0.2-0.4 GSM8K, 0.1-0.3 PRM800K):
- Qwen3-14B
- Llama-3-70B-Instruct-v1.0
- **Top-right cluster** (0.4-0.6 GSM8K, 0.3-0.6 PRM800K):
- DeepSeek-V3-0324
- Llama-4-Maverick-17B-Instruct
- Qwen2.5-72B-Instruct
### Key Observations
- Weaker correlation (r=0.559) compared to SCLI5-GSM8K relationship
- More dispersed data points indicate less consistent relationships
- High-performing models show better alignment with the fitted line
### Interpretation
The moderate correlation suggests that while there's some relationship between GSM8K-SC and PRM800K-SC performance, it's less consistent than the SCLI5-GSM8K relationship. The dispersion of points indicates that models may perform differently across these benchmarks, suggesting varying strengths in different reasoning domains.
---
## Cross-Plot Analysis
1. **Consistency**:
- SCLI5-GSM8K shows strongest correlation (r=0.724)
- GSM8K-PRM800K shows weakest correlation (r=0.559)
2. **Model Performance**:
- Qwen2.5-72B-Instruct consistently performs best across all benchmarks
- Mistral-Small-24B-Instruct-v1.0 consistently performs worst
3. **Trend Lines**:
- Fitted lines in both scatter plots closely follow ideal lines, suggesting linear relationships
- steeper slope in SCLI5-GSM8K plot indicates stronger relationship
## Conclusion
The correlation matrix and scatter plots reveal distinct performance patterns across different reasoning benchmarks. The strong SCLI5-GSM8K relationship suggests shared characteristics in these benchmarks, while the weaker GSM8K-PRM800K relationship indicates more divergent performance characteristics. Model performance tiers are clearly distinguishable, with high-performing models showing consistent excellence across all benchmarks.
DECODING INTELLIGENCE...