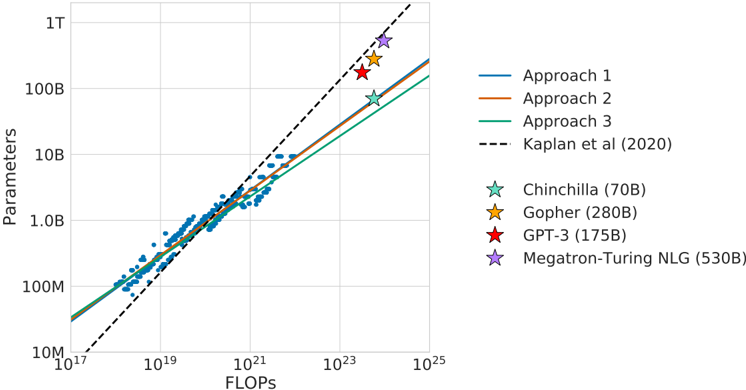
## Scatter Plot: FLOPs vs. Parameters in Language Models
### Overview
The image is a logarithmic scatter plot comparing the relationship between computational FLOPs (floating-point operations) and model parameters for various large language models (LLMs). It includes three theoretical scaling approaches (1, 2, 3) and empirical data points for specific models, alongside a reference line from Kaplan et al. (2020).
---
### Components/Axes
- **X-axis (FLOPs)**: Logarithmic scale from 10¹⁷ to 10²⁵.
- **Y-axis (Parameters)**: Logarithmic scale from 10⁷ to 10¹².
- **Legend**:
- **Approach 1**: Blue line (straight).
- **Approach 2**: Orange line (slightly curved).
- **Approach 3**: Green line (steeper curve).
- **Kaplan et al. (2020)**: Dashed black line.
- **Models**:
- Chinchilla (70B): Teal star.
- Gopher (280B): Yellow star.
- GPT-3 (175B): Red star.
- Megatron-Turing NLG (530B): Purple star.
---
### Detailed Analysis
1. **Trend Lines**:
- **Approach 1 (Blue)**: Linear relationship between FLOPs and parameters.
- **Approach 2 (Orange)**: Slightly curved upward, indicating accelerating parameter growth with FLOPs.
- **Approach 3 (Green)**: Steeper curve, suggesting exponential parameter scaling with FLOPs.
- **Kaplan et al. (2020) (Dashed)**: Baseline trend line starting at ~10¹⁷ FLOPs and 10⁷ parameters, extending to 10²⁵ FLOPs and 10¹² parameters.
2. **Model Data Points**:
- **Chinchilla (70B)**: ~10²¹ FLOPs, ~10¹¹ parameters (above Kaplan line).
- **Gopher (280B)**: ~10²² FLOPs, ~10¹² parameters (above Kaplan line).
- **GPT-3 (175B)**: ~10²³ FLOPs, ~10¹² parameters (above Kaplan line).
- **Megatron-Turing NLG (530B)**: ~10²⁴ FLOPs, ~10¹² parameters (above Kaplan line).
---
### Key Observations
1. **Model Efficiency**: All models exceed the Kaplan et al. (2020) trend line, indicating they achieve higher parameter counts than predicted for their FLOPs.
2. **Scaling Strategies**:
- Approach 3 (green) aligns most closely with GPT-3 and Megatron-Turing NLG, suggesting aggressive parameter scaling.
- Approach 1 (blue) matches smaller models like Chinchilla and Gopher.
3. **Outliers**: GPT-3 (175B) and Megatron-Turing NLG (530B) deviate significantly from the trend lines, highlighting their parameter efficiency.
---
### Interpretation
The data demonstrates that modern LLMs (e.g., GPT-3, Megatron-Turing NLG) scale parameters more efficiently than Kaplan et al.'s 2020 predictions, achieving higher parameter counts for equivalent FLOPs. This suggests advancements in model architecture or training techniques that optimize parameter utilization. The divergence between the trend lines (Approaches 1–3) reflects differing assumptions about computational efficiency, with Approach 3 representing the most resource-intensive scaling strategy. The positioning of models above the Kaplan line underscores a trend toward parameter-rich models despite computational constraints, likely driven by improvements in training methodologies or hardware optimization.