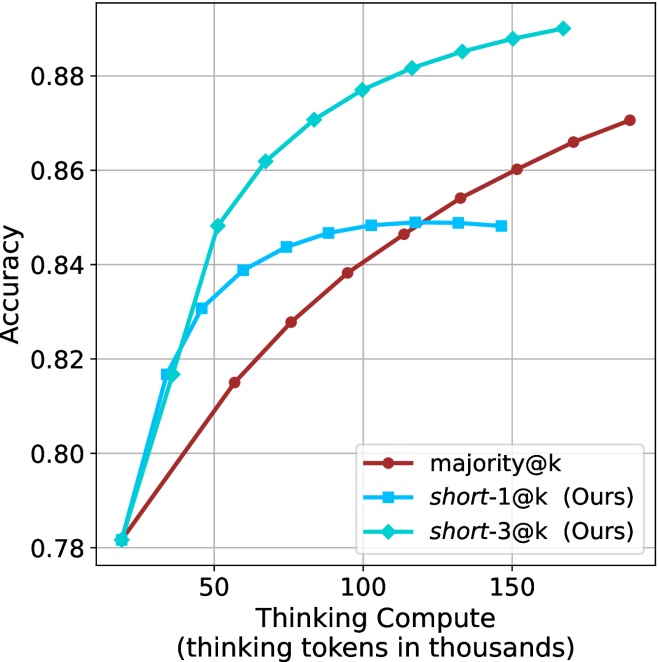
## Line Graph: Accuracy vs. Thinking Compute (Thinking Tokens in Thousands)
### Overview
The graph compares three computational approaches ("majority@k", "short-1@k", "short-3@k") across varying levels of thinking compute (measured in thousands of thinking tokens). Accuracy is measured on a scale from 0.78 to 0.88.
### Components/Axes
- **X-axis**: Thinking Compute (thinking tokens in thousands)
- Scale: 50 → 150 (in thousands)
- Labels: 50, 100, 150
- **Y-axis**: Accuracy
- Scale: 0.78 → 0.88
- Labels: 0.80, 0.82, 0.84, 0.86, 0.88
- **Legend**: Located at bottom-right
- Red: majority@k
- Blue: short-1@k (Ours)
- Green: short-3@k (Ours)
### Detailed Analysis
1. **majority@k (Red Line)**
- Starts at 0.78 accuracy at 50k tokens.
- Increases linearly to ~0.87 accuracy at 150k tokens.
- Key data points:
- 50k: 0.78
- 100k: 0.84
- 150k: 0.87
2. **short-1@k (Blue Line)**
- Begins at 0.82 accuracy at 50k tokens.
- Rises to ~0.85 accuracy at 100k tokens, then plateaus.
- Key data points:
- 50k: 0.82
- 100k: 0.85
- 150k: 0.85
3. **short-3@k (Green Line)**
- Starts at 0.78 accuracy at 50k tokens.
- Sharp upward trajectory to 0.88 accuracy at 150k tokens.
- Key data points:
- 50k: 0.78
- 100k: 0.86
- 150k: 0.88
### Key Observations
- **short-3@k** achieves the highest accuracy (0.88) at maximum compute (150k tokens), outperforming other methods.
- **majority@k** shows steady improvement but remains the lowest-performing method throughout.
- **short-1@k** plateaus at ~0.85 accuracy despite increased compute, suggesting diminishing returns.
- All methods start at similar accuracy levels (0.78–0.82) at 50k tokens but diverge significantly at higher compute levels.
### Interpretation
The data demonstrates that **short-3@k** is the most efficient approach, achieving superior accuracy with minimal compute. Its steep upward trend indicates strong scalability, while **short-1@k**'s plateau suggests limited effectiveness beyond 100k tokens. **majority@k** serves as a baseline, showing linear but suboptimal growth. The divergence between methods highlights trade-offs between computational cost and performance, with **short-3@k** offering the best balance for high-accuracy applications.