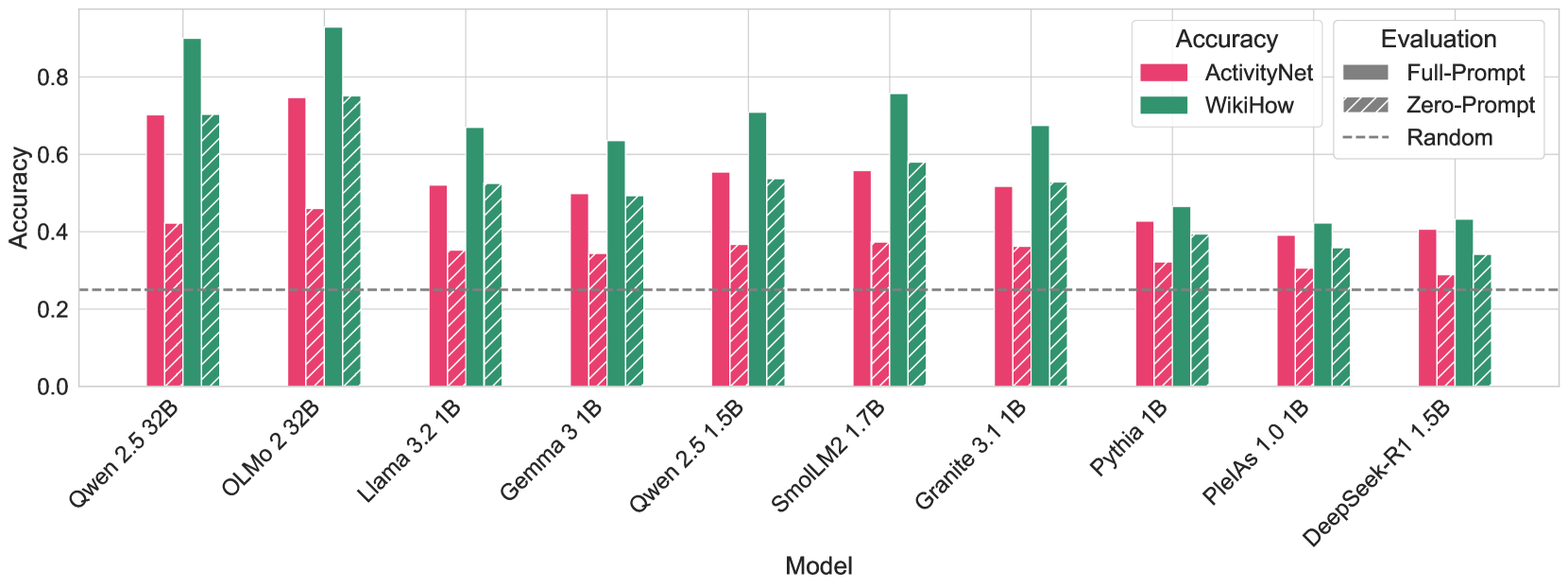
## Bar Chart: Model Accuracy on ActivityNet and WikiHow Datasets
### Overview
The image is a bar chart comparing the accuracy of various language models on two datasets: ActivityNet and WikiHow. The chart also shows the performance of each model under "Zero-Prompt" conditions, and a "Random" baseline. The x-axis represents different language models, and the y-axis represents accuracy, ranging from 0.0 to 0.8.
### Components/Axes
* **X-axis:** Model (Qwen 2.5 32B, OLMo 2 32B, Llama 3.2 1B, Gemma 3 1B, Qwen 2.5 1.5B, SmolLM2 1.7B, Granite 3.1 1B, Pythia 1B, PlelAs 1.0 1B, DeepSeek-R1 1.5B)
* **Y-axis:** Accuracy (scale from 0.0 to 0.8, incrementing by 0.2)
* **Legend (top-right):**
* **Accuracy:**
* ActivityNet (Pink/Red)
* WikiHow (Green)
* **Evaluation:**
* Full-Prompt (Solid Gray) - Not directly represented in the chart, but implied as the standard ActivityNet and WikiHow bars.
* Zero-Prompt (Hatched Gray) - Represented by hatched bars corresponding to each model.
* Random (Dashed Gray Line) - Represented by a horizontal dashed line.
### Detailed Analysis
**Data Series Trends and Values:**
* **ActivityNet (Pink/Red Bars):** Generally, the accuracy varies across models.
* Qwen 2.5 32B: ~0.7
* OLMo 2 32B: ~0.42
* Llama 3.2 1B: ~0.52
* Gemma 3 1B: ~0.5
* Qwen 2.5 1.5B: ~0.55
* SmolLM2 1.7B: ~0.56
* Granite 3.1 1B: ~0.52
* Pythia 1B: ~0.42
* PlelAs 1.0 1B: ~0.38
* DeepSeek-R1 1.5B: ~0.28
* **WikiHow (Green Bars):** Generally, the accuracy is higher than ActivityNet for most models.
* Qwen 2.5 32B: ~0.75
* OLMo 2 32B: ~0.92
* Llama 3.2 1B: ~0.68
* Gemma 3 1B: ~0.62
* Qwen 2.5 1.5B: ~0.7
* SmolLM2 1.7B: ~0.62
* Granite 3.1 1B: ~0.68
* Pythia 1B: ~0.4
* PlelAs 1.0 1B: ~0.42
* DeepSeek-R1 1.5B: ~0.42
* **Zero-Prompt (Hatched Bars):** The hatched bars represent the "Zero-Prompt" evaluation. The color of the hatching matches the color of the solid bar it is paired with.
* Qwen 2.5 32B: ~0.75
* OLMo 2 32B: ~0.73
* Llama 3.2 1B: ~0.35
* Gemma 3 1B: ~0.32
* Qwen 2.5 1.5B: ~0.38
* SmolLM2 1.7B: ~0.6
* Granite 3.1 1B: ~0.5
* Pythia 1B: ~0.3
* PlelAs 1.0 1B: ~0.3
* DeepSeek-R1 1.5B: ~0.3
* **Random (Dashed Gray Line):** A horizontal line at approximately 0.25 accuracy.
### Key Observations
* OLMo 2 32B achieves the highest accuracy on the WikiHow dataset.
* DeepSeek-R1 1.5B has the lowest accuracy on the ActivityNet dataset.
* The "Zero-Prompt" evaluation generally results in lower accuracy compared to the "Full-Prompt" evaluation, except for SmolLM2 1.7B on ActivityNet.
* The performance of models varies significantly depending on the dataset.
* The "Random" baseline provides a reference point for the minimum expected accuracy.
### Interpretation
The chart illustrates the performance of different language models on two distinct datasets, ActivityNet and WikiHow. The comparison highlights the models' ability to generalize across different types of data. The "Zero-Prompt" evaluation provides insights into the models' inherent knowledge and ability to perform tasks without specific instructions. The "Random" baseline helps to contextualize the models' performance, indicating whether they are performing better than random chance.
The data suggests that some models are better suited for certain datasets than others. For example, OLMo 2 32B performs exceptionally well on WikiHow but not as well on ActivityNet. This could be due to the nature of the data or the model's architecture. The "Zero-Prompt" evaluation reveals the models' ability to perform tasks without explicit instructions, which is an important aspect of their overall intelligence.
The chart also reveals some interesting anomalies. For example, SmolLM2 1.7B performs better on ActivityNet in the "Zero-Prompt" evaluation than in the "Full-Prompt" evaluation. This could be due to the model's ability to leverage its inherent knowledge to perform the task without being constrained by specific instructions.