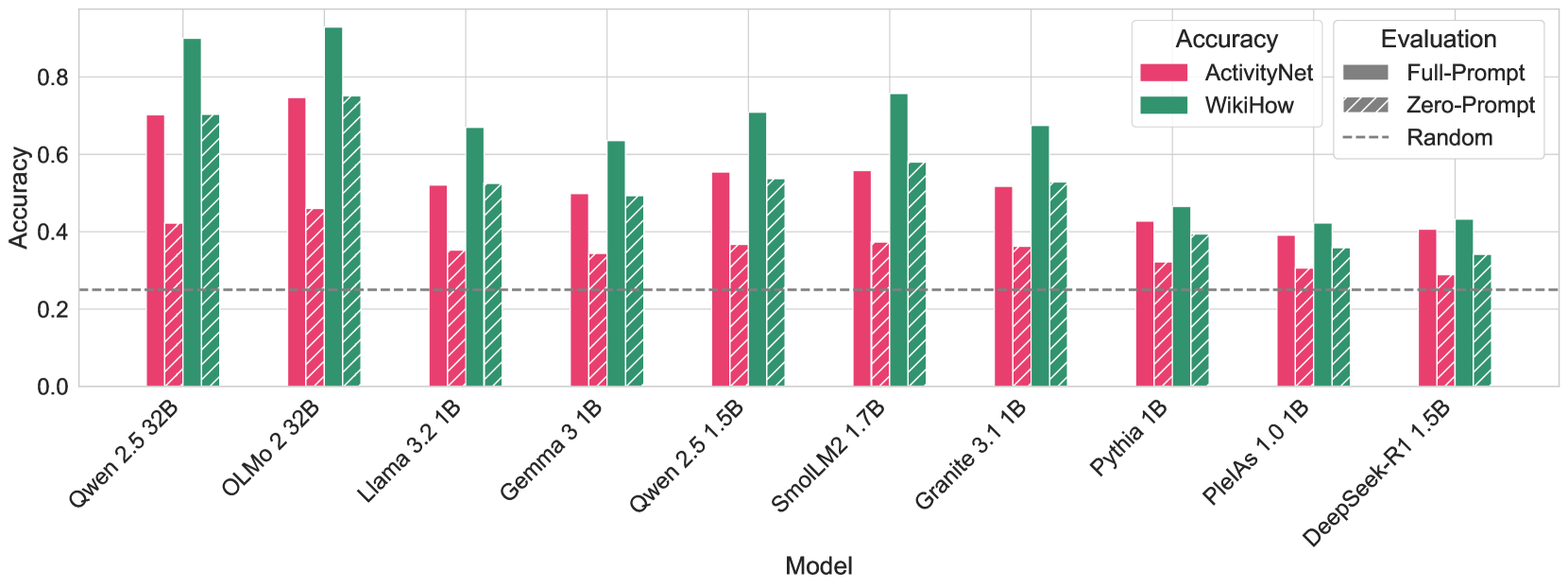
## Grouped Bar Chart: Model Accuracy Comparison on ActivityNet and WikiHow Datasets
### Overview
The image is a grouped bar chart comparing the accuracy of ten different language models on two datasets: ActivityNet and WikiHow. Each model's performance is shown under two evaluation conditions: "Full-Prompt" and "Zero-Prompt." A dashed line indicates a "Random" baseline accuracy.
### Components/Axes
* **X-Axis (Horizontal):** Labeled "Model." It lists ten specific language models. From left to right:
1. Qwen 2.5 32B
2. OLMo 2 32B
3. Llama 3.2 1B
4. Gemma 3 1B
5. Qwen 2.5 1.5B
6. SmolLM2 1.7B
7. Granite 3.1 1B
8. Pythia 1B
9. PleIAs 1.0 1B
10. DeepSeek-R1 1.5B
* **Y-Axis (Vertical):** Labeled "Accuracy." The scale runs from 0.0 to approximately 0.9, with major gridlines at 0.0, 0.2, 0.4, 0.6, and 0.8.
* **Legend (Top-Right):**
* **Accuracy (Color):**
* Pink/Red bars represent the **ActivityNet** dataset.
* Green/Teal bars represent the **WikiHow** dataset.
* **Evaluation (Pattern):**
* Solid bars represent **Full-Prompt** evaluation.
* Diagonally hatched bars represent **Zero-Prompt** evaluation.
* A dashed grey line represents the **Random** baseline.
* **Baseline:** A horizontal dashed grey line is positioned at an accuracy of approximately **0.25**, labeled "Random" in the legend.
### Detailed Analysis
For each model, there are four bars: two for ActivityNet (Full-Prompt solid, Zero-Prompt hatched) and two for WikiHow (Full-Prompt solid, Zero-Prompt hatched). Values are approximate visual estimates.
1. **Qwen 2.5 32B:**
* *Trend:* Strong performance, with WikiHow scores notably higher than ActivityNet. Full-Prompt outperforms Zero-Prompt on both datasets.
* *Values:* ActivityNet Full-Prompt ~0.70, Zero-Prompt ~0.42. WikiHow Full-Prompt ~0.90, Zero-Prompt ~0.70.
2. **OLMo 2 32B:**
* *Trend:* Highest overall performance on the chart. WikiHow Full-Prompt is the tallest bar. Similar pattern to Qwen 2.5 32B.
* *Values:* ActivityNet Full-Prompt ~0.75, Zero-Prompt ~0.46. WikiHow Full-Prompt ~0.92, Zero-Prompt ~0.75.
3. **Llama 3.2 1B:**
* *Trend:* Moderate performance. WikiHow scores are higher than ActivityNet. The gap between Full-Prompt and Zero-Prompt is smaller than for the larger models.
* *Values:* ActivityNet Full-Prompt ~0.52, Zero-Prompt ~0.35. WikiHow Full-Prompt ~0.67, Zero-Prompt ~0.52.
4. **Gemma 3 1B:**
* *Trend:* Similar profile to Llama 3.2 1B, with slightly lower scores.
* *Values:* ActivityNet Full-Prompt ~0.50, Zero-Prompt ~0.34. WikiHow Full-Prompt ~0.63, Zero-Prompt ~0.49.
5. **Qwen 2.5 1.5B:**
* *Trend:* Performance is between the 1B and 32B models of its family. Clear advantage for WikiHow and Full-Prompt.
* *Values:* ActivityNet Full-Prompt ~0.55, Zero-Prompt ~0.37. WikiHow Full-Prompt ~0.71, Zero-Prompt ~0.54.
6. **SmolLM2 1.7B:**
* *Trend:* Notably strong performance for its size, especially on WikiHow Full-Prompt.
* *Values:* ActivityNet Full-Prompt ~0.56, Zero-Prompt ~0.37. WikiHow Full-Prompt ~0.76, Zero-Prompt ~0.58.
7. **Granite 3.1 1B:**
* *Trend:* Moderate performance, consistent with other 1B-class models.
* *Values:* ActivityNet Full-Prompt ~0.52, Zero-Prompt ~0.36. WikiHow Full-Prompt ~0.68, Zero-Prompt ~0.53.
8. **Pythia 1B:**
* *Trend:* Lower performance tier. The gap between datasets and prompt methods is less pronounced.
* *Values:* ActivityNet Full-Prompt ~0.43, Zero-Prompt ~0.32. WikiHow Full-Prompt ~0.47, Zero-Prompt ~0.39.
9. **PleIAs 1.0 1B:**
* *Trend:* Among the lowest performing models shown. Scores are clustered closer together.
* *Values:* ActivityNet Full-Prompt ~0.39, Zero-Prompt ~0.31. WikiHow Full-Prompt ~0.42, Zero-Prompt ~0.36.
10. **DeepSeek-R1 1.5B:**
* *Trend:* Similar performance level to PleIAs 1.0 1B.
* *Values:* ActivityNet Full-Prompt ~0.41, Zero-Prompt ~0.29. WikiHow Full-Prompt ~0.43, Zero-Prompt ~0.34.
### Key Observations
* **Dataset Difficulty:** For every single model, accuracy on the **WikiHow** dataset (green bars) is higher than on the **ActivityNet** dataset (pink bars). This suggests WikiHow is an easier task for these models.
* **Prompting Effect:** For every model and both datasets, **Full-Prompt** evaluation (solid bars) yields higher accuracy than **Zero-Prompt** evaluation (hatched bars). The performance drop from Full-Prompt to Zero-Prompt is generally more severe for the larger, higher-performing models.
* **Model Scale:** The two largest models (Qwen 2.5 32B and OLMo 2 32B) significantly outperform all the smaller models (1B-1.7B range).
* **Random Baseline:** All models perform above the random baseline of ~0.25, even under Zero-Prompt conditions.
* **Outlier:** SmolLM2 1.7B shows particularly strong performance for its size class, especially on WikiHow with Full-Prompt, rivaling some scores from the much larger 32B models.
### Interpretation
This chart demonstrates two clear, consistent trends in language model evaluation:
1. **Task Dependency:** Model performance is highly dependent on the specific dataset or task. The systematic advantage on WikiHow suggests it may involve more structured or common-knowledge procedural text compared to ActivityNet, which likely involves more complex, real-world video-based activity understanding.
2. **Prompt Sensitivity:** Providing a full prompt significantly boosts accuracy across the board. The larger performance drop for bigger models when moving to Zero-Prompt might indicate they are better at leveraging provided context, and thus suffer more when that context is removed.
The data suggests that for these procedural understanding tasks, both the choice of model scale and the evaluation setup (prompting strategy) are critical factors. The consistent hierarchy (WikiHow > ActivityNet, Full-Prompt > Zero-Prompt) provides a reliable benchmark for comparing these models. The strong showing of SmolLM2 1.7B is notable, indicating that architecture or training data can sometimes compensate for smaller parameter count.