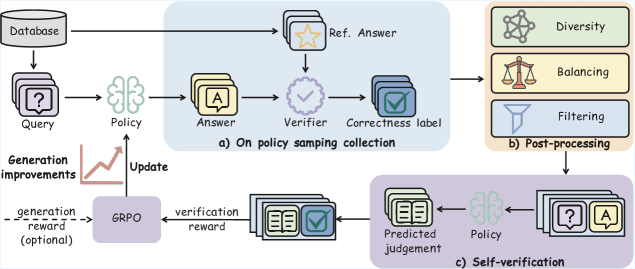
## Flowchart: Answer Generation and Verification System
### Overview
The flowchart depicts a multi-stage system for generating, verifying, and refining answers to queries using a database and policy-based mechanisms. It includes three primary phases: (a) Policy Sampling Collection, (b) Post-processing, and (c) Self-verification. Arrows indicate directional flow, and components are interconnected through feedback loops and conditional updates.
---
### Components/Axes
1. **Database**: Top-left node, feeds queries into the system.
2. **Query**: Purple box with a question mark, receives input from the database.
3. **Policy**: Brain icon, generates answers based on queries.
4. **Answer**: Yellow box with "A", output of the policy.
5. **Verifier**: Purple checkmark icon, evaluates answers against reference answers.
6. **Correctness Label**: Blue box with a green checkmark, outputs verification results.
7. **Ref. Answer**: Yellow star icon, reference standard for verification.
8. **Diversity**: Top-right node with a network icon, balances answer variety.
9. **Balancing**: Scale icon, ensures equitable answer distribution.
10. **Filtering**: Funnel icon, removes low-quality answers.
11. **GRPO**: Purple box labeled "GRPO", handles generation reward (optional).
12. **Predicted Judgement**: Book icon with checkmark, self-verification output.
13. **Policy Update**: Upward arrow, refines policy based on feedback.
---
### Detailed Analysis
- **Phase a) Policy Sampling Collection**:
- Queries from the database trigger the policy to generate answers.
- Answers are verified against reference answers, producing correctness labels.
- Generation improvements (optional) update the policy via GRPO using verification rewards.
- **Phase b) Post-processing**:
- Correctness-labeled answers undergo diversity balancing and filtering to optimize quality and variety.
- **Phase c) Self-verification**:
- The policy generates predicted judgements, which are cross-checked against answers to refine the policy iteratively.
---
### Key Observations
1. **Feedback Loops**: The system uses verification results to update the policy (e.g., GRPO adjustments).
2. **Optional Component**: Generation reward via GRPO is marked as optional, suggesting flexibility in implementation.
3. **Quality Control**: Post-processing steps (diversity, balancing, filtering) ensure answers meet quality and diversity criteria.
4. **Self-verification**: The policy evaluates its own outputs, creating a closed-loop improvement mechanism.
---
### Interpretation
This flowchart represents a reinforcement learning framework for answer generation, emphasizing iterative policy refinement. The **Verifier** and **Self-verification** components suggest a focus on accuracy and reliability, while **Diversity** and **Balancing** address coverage and fairness. The **GRPO** module implies optimization via reward modeling, though its optional nature indicates adaptability to different use cases. The system’s closed-loop design highlights its capacity for continuous improvement, critical for dynamic or high-stakes applications like QA systems or automated reasoning tools.