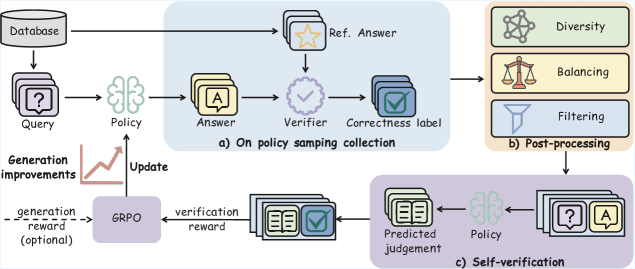
## Diagram: Policy Sampling and Self-Verification Process
### Overview
The image illustrates a system involving policy sampling, post-processing, and self-verification. It outlines the flow of data and processes from a database query to a final predicted judgement, incorporating elements of diversity, balancing, and filtering.
### Components/Axes
* **Database:** The starting point of the process.
* **Query:** A stack of documents labeled with a question mark "?".
* **Policy:** Represented by a brain icon, indicating a decision-making process.
* **Answer:** A stack of documents labeled with the letter "A".
* **Ref. Answer:** A stack of documents with a star icon.
* **Verifier:** A circle with a checkmark inside.
* **Correctness label:** A stack of documents with a checkmark.
* **Diversity:** Represented by a network icon.
* **Balancing:** Represented by a scale icon.
* **Filtering:** Represented by a filter icon.
* **Predicted judgement:** A stack of documents with book icons.
* **GRPO:** A rectangular block representing a process.
* **Generation improvements:** Text label with an arrow pointing to an upward sloping line.
* **Update:** Text label with an arrow pointing upwards from GRPO to Policy.
* **generation reward (optional):** Text label with a dashed arrow pointing from GRPO to Generation improvements.
* **verification reward:** Text label with an arrow pointing from Predicted judgement to GRPO.
* **a) On policy samping collection:** Text label for the top-right section.
* **b) Post-processing:** Text label for the middle-right section.
* **c) Self-verification:** Text label for the bottom section.
### Detailed Analysis
1. **Initial Stage:**
* The process begins with a "Database" from which a "Query" is generated.
* The "Query" is then processed by a "Policy" to produce an "Answer".
2. **Policy Sampling Collection (a):**
* The "Answer" is compared with a "Ref. Answer" using a "Verifier".
* The result is a "Correctness label".
3. **Post-processing (b):**
* The "Correctness label" undergoes "Diversity", "Balancing", and "Filtering".
4. **Self-verification (c):**
* The output from post-processing leads to "Predicted judgement".
* The "Predicted judgement" is fed back into the "Policy" for self-verification.
5. **GRPO and Feedback:**
* "GRPO" receives "verification reward" from "Predicted judgement".
* "GRPO" provides an "Update" to the "Policy" and an optional "generation reward" to "Generation improvements".
6. **Generation improvements:**
* The line slopes upwards, indicating an increase.
### Key Observations
* The diagram illustrates a closed-loop system where the output of the process is used to refine the policy.
* The "GRPO" plays a central role in updating the policy based on the "verification reward".
* Post-processing steps like "Diversity", "Balancing", and "Filtering" are crucial for refining the output.
### Interpretation
The diagram represents a reinforcement learning or iterative refinement process. The system uses a policy to generate answers to queries, verifies the correctness of these answers, and then uses the verification results to update the policy. The inclusion of diversity, balancing, and filtering suggests an effort to improve the quality and robustness of the generated answers. The GRPO (likely Gradient Policy Optimization) component is responsible for learning from the verification rewards and updating the policy accordingly. The optional generation reward suggests an additional mechanism to incentivize the generation of better answers. The self-verification loop indicates a system that continuously learns and improves its performance over time.