\n
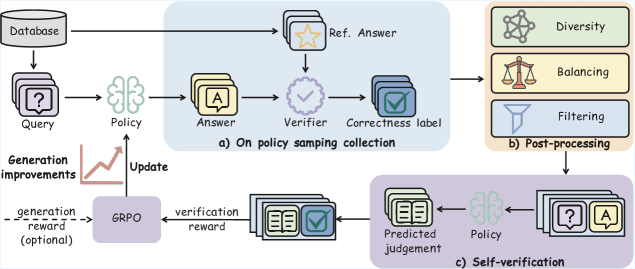
## Diagram: GRPO Training Pipeline
### Overview
The image depicts a diagram illustrating the training pipeline for a Generative Retrieval-Policy Optimization (GRPO) model. The pipeline consists of three main stages: (a) On-policy sampling collection, (b) Post-processing, and (c) Self-verification. The diagram shows the flow of data and feedback loops involved in improving the model's performance.
### Components/Axes
The diagram includes the following components:
* **Database:** A cylindrical shape representing the data source.
* **Query:** Represented by a question mark inside a document icon.
* **Policy:** Represented by a brain-shaped icon.
* **Answer:** Represented by the letter "A" inside a document icon.
* **Ref. Answer:** Represented by a star inside a document icon.
* **Verifier:** Represented by a checkmark inside a cloud-shaped icon.
* **Correctness label:** Represented by a document icon with a checkmark.
* **Diversity:** Represented by a network-like icon.
* **Balancing:** Represented by a scale icon.
* **Filtering:** Represented by a funnel icon.
* **GRPO:** A rectangular box labeled "GRPO".
* **Generation improvements:** A line graph showing an upward trend.
* **Update:** A label indicating the direction of the improvement signal.
* **Generation reward (optional):** A label indicating an optional reward signal.
* **Verification reward:** A label indicating a reward signal.
* **Predicted judgement:** Represented by a document icon with a checkmark.
The diagram is divided into three sections labeled (a), (b), and (c), representing the different stages of the pipeline.
### Detailed Analysis or Content Details
**Section (a): On-policy sampling collection**
* A "Query" is sent to the "Policy".
* The "Policy" generates an "Answer".
* The "Answer" is compared to a "Ref. Answer" using a "Verifier".
* The "Verifier" provides a "Correctness label".
* The "Correctness label" is used for post-processing.
**Section (b): Post-processing**
* The "Correctness label" is fed into three post-processing steps: "Diversity", "Balancing", and "Filtering".
* These steps refine the data before it is used for training.
**Section (c): Self-verification**
* The "Policy" generates a "Predicted judgement".
* The "Predicted judgement" is compared to the "Ref. Answer".
* A "Verification reward" is generated based on the comparison.
* The "Verification reward" and an optional "Generation reward" are fed into the "GRPO" model.
* The "GRPO" model updates the "Policy" based on the rewards, leading to "Generation improvements".
* The "Update" signal flows back to the "Policy".
The "Generation improvements" are visualized as an upward-sloping line graph, indicating that the model's performance is improving over time.
### Key Observations
* The pipeline involves a feedback loop where the model's predictions are verified and used to improve its policy.
* The post-processing steps aim to improve the quality and diversity of the generated answers.
* The optional "Generation reward" suggests that the model can be further improved by incorporating additional reward signals.
* The diagram highlights the importance of both generation and verification in the training process.
### Interpretation
The diagram illustrates a reinforcement learning approach to training a generative model for question answering. The GRPO model learns to generate answers by receiving rewards based on their correctness and quality. The self-verification stage allows the model to assess its own performance and improve its policy accordingly. The post-processing steps ensure that the generated answers are diverse, balanced, and filtered for relevance. The upward trend in "Generation improvements" suggests that the training process is effective in enhancing the model's performance. The diagram emphasizes the iterative nature of the training process, where the model continuously learns and improves through feedback and refinement. The inclusion of an optional generation reward suggests a flexible framework that can be adapted to different reward structures and training objectives. The overall design suggests a sophisticated system aimed at producing high-quality, reliable answers to complex queries.