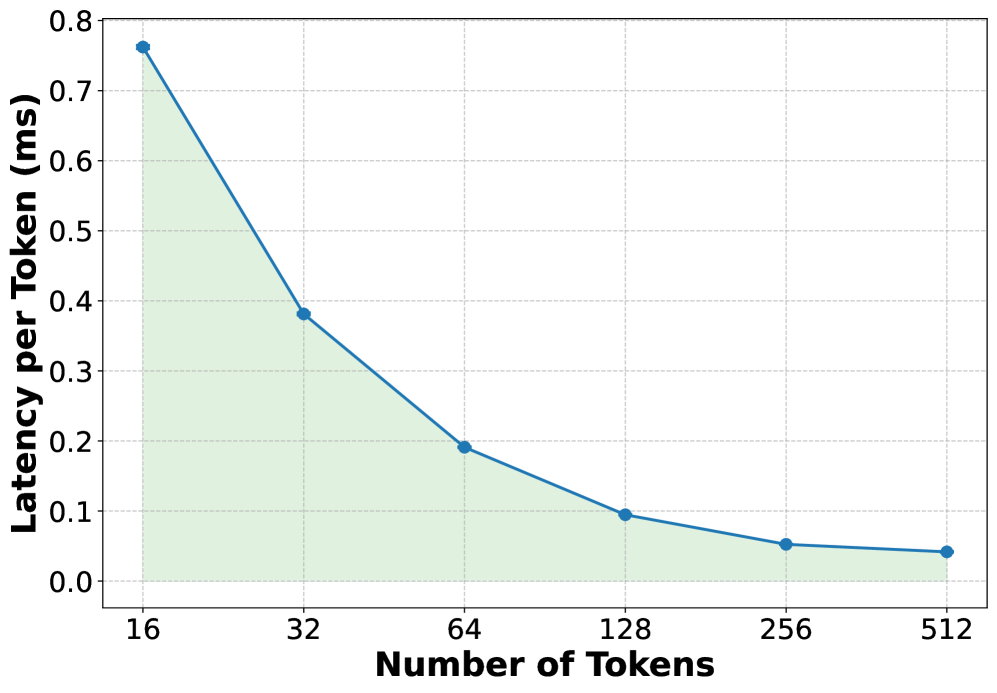
## Line Chart: Latency per Token vs. Number of Tokens
### Overview
The image is a line chart showing the relationship between the number of tokens and the latency per token (in milliseconds). The chart illustrates a decreasing trend in latency as the number of tokens increases. The area under the line is shaded in light green.
### Components/Axes
* **X-axis:** "Number of Tokens" with values 16, 32, 64, 128, 256, and 512.
* **Y-axis:** "Latency per Token (ms)" with values ranging from 0.0 to 0.8, in increments of 0.1.
* **Data Series:** A single blue line representing the latency per token. The area under the curve is shaded light green.
### Detailed Analysis
The blue line shows the latency per token as the number of tokens increases.
* **16 Tokens:** Latency is approximately 0.76 ms.
* **32 Tokens:** Latency is approximately 0.38 ms.
* **64 Tokens:** Latency is approximately 0.19 ms.
* **128 Tokens:** Latency is approximately 0.09 ms.
* **256 Tokens:** Latency is approximately 0.05 ms.
* **512 Tokens:** Latency is approximately 0.04 ms.
The line slopes downward, indicating a negative correlation between the number of tokens and latency per token. The rate of decrease slows as the number of tokens increases.
### Key Observations
* The latency per token decreases significantly as the number of tokens increases from 16 to 64.
* The rate of decrease in latency slows down as the number of tokens increases beyond 128.
* The latency appears to plateau around 0.04-0.05 ms for 256 and 512 tokens.
### Interpretation
The chart suggests that increasing the number of tokens can reduce the latency per token, especially at lower token counts. However, there appears to be a point of diminishing returns, where increasing the number of tokens further does not significantly reduce latency. This could be due to overhead costs associated with processing a large number of tokens, or limitations in the processing architecture. The data indicates that optimizing for a token count between 128 and 256 may provide a good balance between token count and latency.