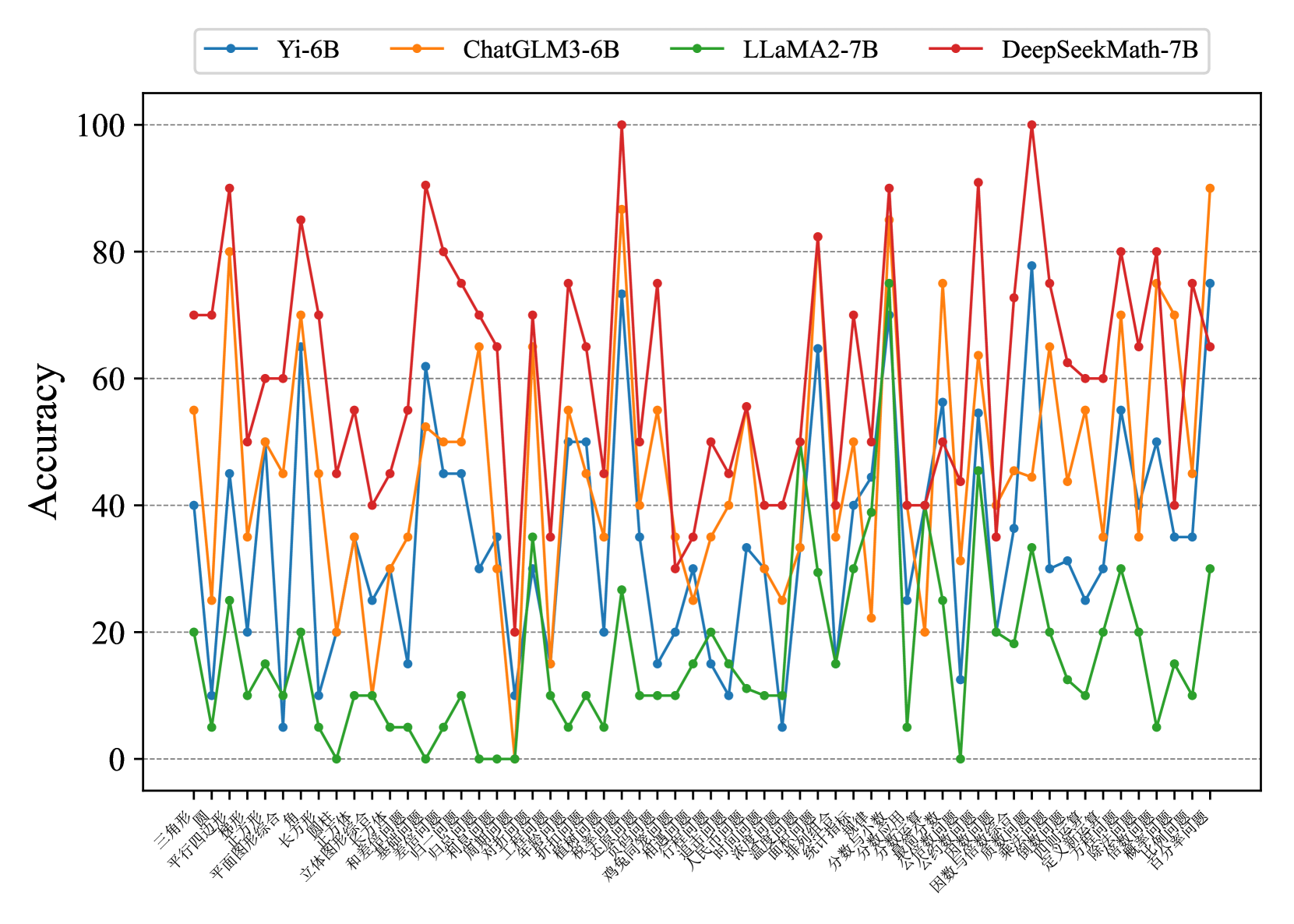
\n
## Line Chart: Model Accuracy on Math Problems
### Overview
This line chart compares the accuracy of four different language models (Yi-6B, ChatGLM3-6B, LLaMA2-7B, and DeepSeekMath-7B) across a series of math problems. The x-axis represents the math problems, labeled in Chinese characters, and the y-axis represents the accuracy, ranging from 0 to 100.
### Components/Axes
* **Y-axis Title:** Accuracy
* **X-axis Title:** (Chinese characters representing math problem types - see "Detailed Analysis" for approximate translations)
* **Legend:** Located at the top-center of the chart.
* Yi-6B (Light Blue Line)
* ChatGLM3-6B (Red Line)
* LLaMA2-7B (Green Line)
* DeepSeekMath-7B (Orange Line)
* **Y-axis Scale:** Linear, from 0 to 100, with increments of 20.
* **X-axis Scale:** Categorical, representing different math problems. The labels are in Chinese.
### Detailed Analysis
The chart displays accuracy scores for each model on each problem. The x-axis labels, translated approximately, are as follows (with uncertainty due to translation):
1. 三角形 (Triangle)
2. 平方和差 (Sum and Difference of Squares)
3. 平面向量 (Plane Vector)
4. 立体几何 (Solid Geometry)
5. 和 (Sum)
6. 不等式 (Inequality)
7. 函数 (Function)
8. 数列 (Sequence)
9. 三角函数 (Trigonometric Function)
10. 导数 (Derivative)
11. 积分 (Integral)
12. 极限 (Limit)
13. 概率 (Probability)
14. 统计 (Statistics)
15. 向量 (Vector)
16. 几何 (Geometry)
17. 计数 (Counting)
18. 组合 (Combination)
19. 概率 (Probability) - *Repeated*
20. 统计 (Statistics) - *Repeated*
21. 抽样 (Sampling)
22. 期望 (Expectation)
23. 方差 (Variance)
24. 离散 (Discrete)
25. 连续 (Continuous)
Here's a breakdown of the trends and approximate accuracy values for each model:
* **Yi-6B (Light Blue):** Generally maintains an accuracy between 20-40%, with some fluctuations. It shows a peak of approximately 50% around the "导数" (Derivative) problem.
* **ChatGLM3-6B (Red):** Exhibits the highest overall accuracy, frequently exceeding 80%. It has several peaks close to 100% on problems like "立体几何" (Solid Geometry), "和" (Sum), "不等式" (Inequality), and "积分" (Integral). It dips to around 30% on "三角形" (Triangle).
* **LLaMA2-7B (Green):** Shows the lowest accuracy, generally below 30%. It has a few peaks around 40% but remains consistently lower than the other models. It reaches a minimum near 0% on the last problem "连续" (Continuous).
* **DeepSeekMath-7B (Orange):** Performs better than LLaMA2-7B but generally lower than Yi-6B and ChatGLM3-6B. It fluctuates between 30-70%, with peaks around 70% on problems like "立体几何" (Solid Geometry) and "和" (Sum).
### Key Observations
* ChatGLM3-6B consistently outperforms the other models across most problems.
* LLaMA2-7B consistently underperforms, indicating a lower capability in solving these math problems.
* DeepSeekMath-7B shows moderate performance, positioned between Yi-6B and ChatGLM3-6B.
* There is significant variation in accuracy across different problem types for all models. Some problems are consistently easier (higher accuracy) than others.
* The repeated "概率" (Probability) and "统计" (Statistics) problems show similar accuracy scores for each model, suggesting consistency in performance on these topics.
### Interpretation
The data suggests that ChatGLM3-6B is the most proficient model for solving the presented set of math problems, while LLaMA2-7B struggles significantly. The performance differences likely stem from variations in model architecture, training data, and optimization strategies. The fluctuations in accuracy across different problem types indicate that the models have varying strengths and weaknesses in specific mathematical areas. The fact that DeepSeekMath-7B, designed for mathematical tasks, performs better than the general-purpose LLaMA2-7B but not as well as ChatGLM3-6B suggests that specialized training can improve performance, but the quality of the training data and model design are crucial. The repeated problems provide a check for consistency, and the similar results suggest the models are not simply overfitting to specific instances. This chart provides a comparative analysis of model capabilities in a mathematical domain, highlighting the importance of model selection for specific tasks.