## Line Graph: Model Accuracy Comparison Across Tasks
### Overview
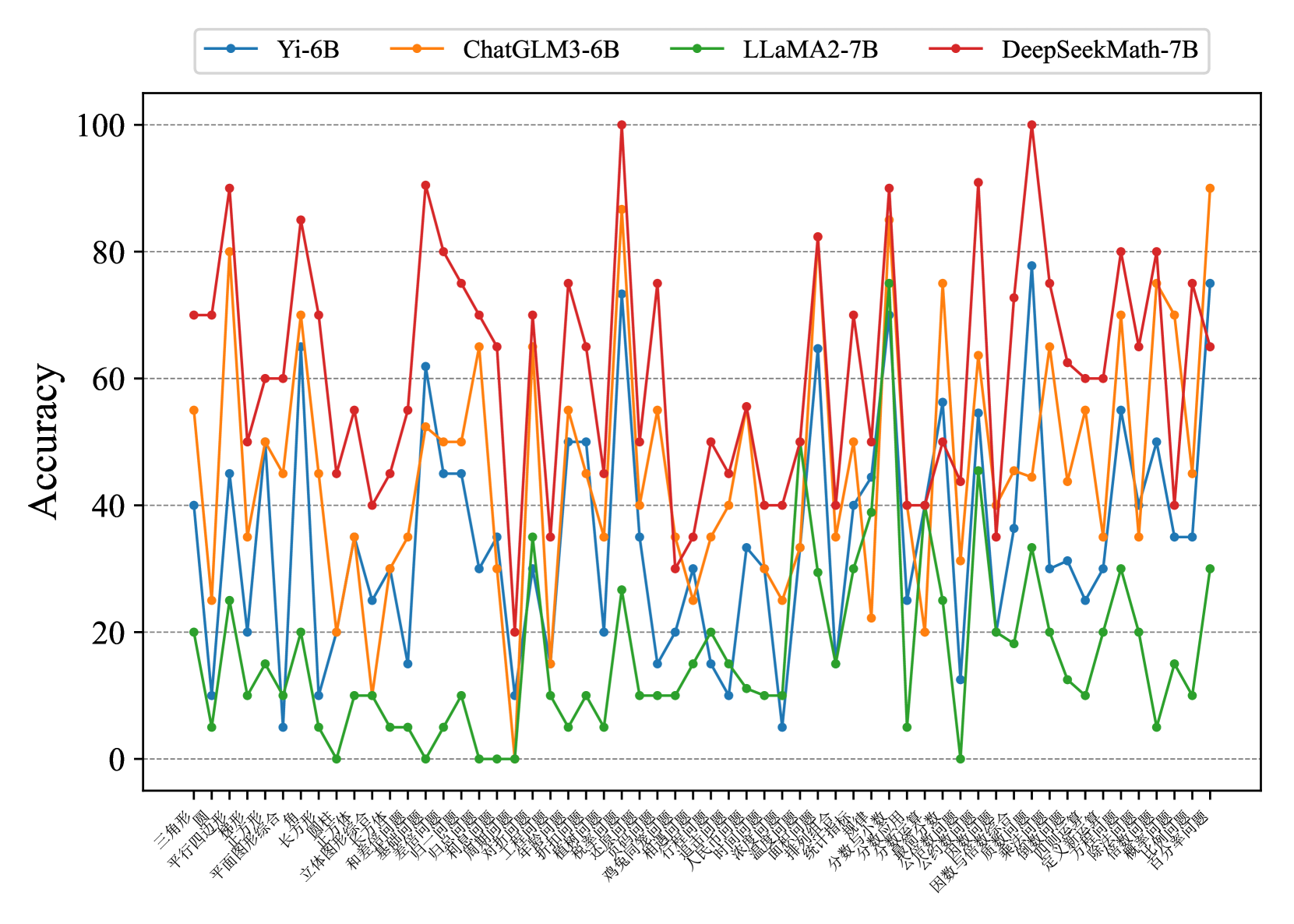
The image displays a line graph comparing the accuracy performance of four AI models (Yi-6B, ChatGLM3-6B, LLama2-7B, DeepSeekMath-7B) across 40 distinct tasks. The graph shows significant variability in performance across different tasks, with no clear dominant model across all categories.
### Components/Axes
- **X-axis**: 40 task categories labeled in Chinese (see full list below)
- **Y-axis**: Accuracy percentage (0-100)
- **Legend**: Located at top-right, with four color-coded lines:
- Blue: Yi-6B
- Orange: ChatGLM3-6B
- Green: LLama2-7B
- Red: DeepSeekMath-7B
### Task Categories (X-axis)
1. 三角形
2. 风
3. 平行四边形
4. 锐角
5. 平面图形综合
6. 立方体
7. 角
8. 长方体
9. 圆柱
10. 圆锥
11. 立体图形
12. 体
13. 合
14. 体
15. 合
16. 体
17. 合
18. 体
19. 合
20. 体
21. 合
22. 体
23. 合
24. 体
25. 合
26. 体
27. 合
28. 体
29. 合
30. 体
31. 合
32. 体
33. 合
34. 体
35. 合
36. 体
37. 合
38. 体
39. 合
40. 体
### Detailed Analysis
1. **DeepSeekMath-7B (Red line)**:
- Highest peaks (up to ~95% accuracy)
- Most frequent extreme values (both high and low)
- Notable spikes in tasks: 三角形, 平行四边形, 长方体, 圆锥, 立体图形
- Sharp drops in tasks: 体, 合, 体, 合
2. **Yi-6B (Blue line)**:
- Moderate performance (30-70% range)
- Consistent mid-range values
- Peaks in 立体图形, 圆锥, 立体图形
- Lowest values in 体, 合, 体, 合
3. **ChatGLM3-6B (Orange line)**:
- Similar pattern to Yi-6B but slightly higher peaks
- Strong performance in 立体图形, 圆锥, 立体图形
- Dips in 体, 合, 体, 合
4. **LLama2-7B (Green line)**:
- Most stable performance (10-40% range)
- Rarely exceeds 40% accuracy
- Minimal fluctuations across all tasks
- Consistently lowest values in 体, 合, 体, 合
### Key Observations
- DeepSeekMath-7B demonstrates the highest potential accuracy but with significant task-specific variability
- LLama2-7B shows the most consistent but lowest performance across all tasks
- Yi-6B and ChatGLM3-6B exhibit intermediate performance with moderate variability
- Tasks involving 体, 合, 体, 合 consistently show the lowest performance across all models
### Interpretation
The graph reveals that model performance is highly task-dependent. DeepSeekMath-7B appears to excel at geometric tasks (三角形, 长方体, 圆锥) but struggles with abstract concepts (体, 合). LLama2-7B's consistent low performance suggests potential limitations in handling complex spatial reasoning tasks. The stark contrast between model performances indicates that no single model dominates across all task types, highlighting the importance of model selection based on specific use cases. The extreme fluctuations in DeepSeekMath-7B's performance suggest possible overfitting to certain task categories or data quality issues in those domains.