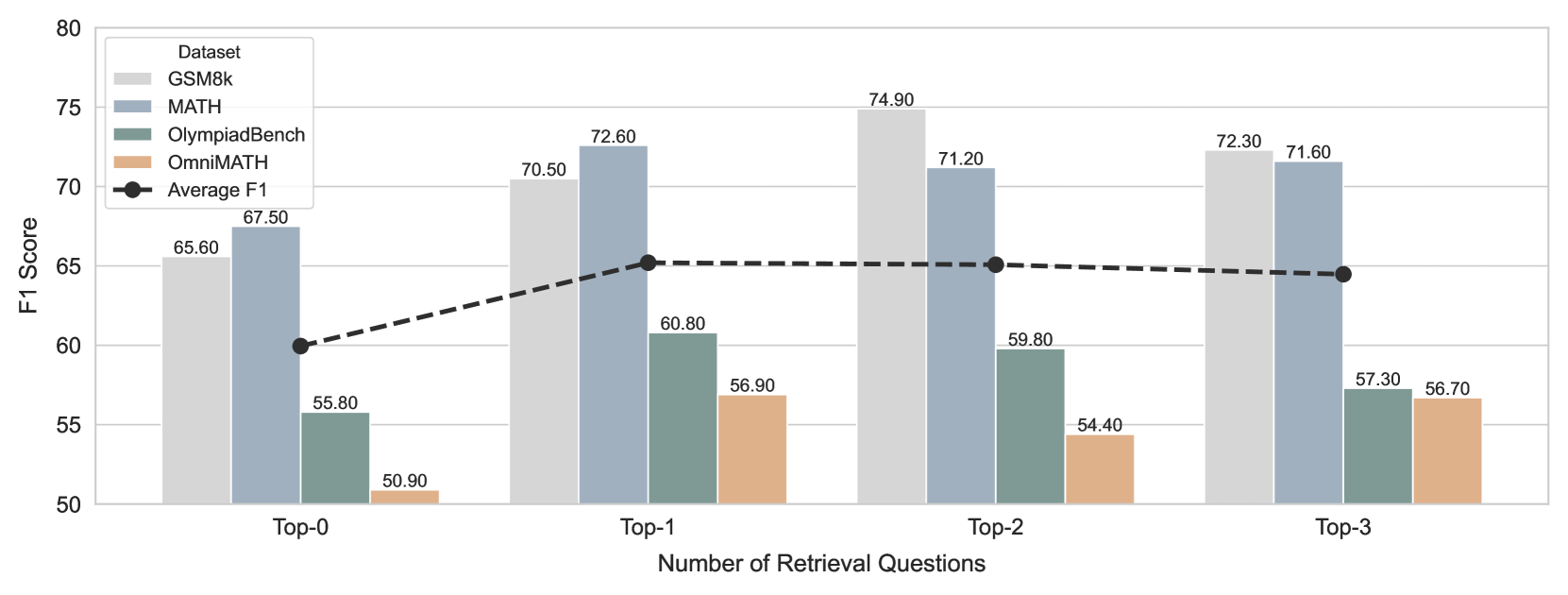
## Bar Chart with Line Plot: F1 Score by Dataset and Number of Retrieval Questions
### Overview
This image displays a bar chart overlaid with a line plot, illustrating the F1 scores for different datasets across varying numbers of retrieval questions. The x-axis represents the "Number of Retrieval Questions" categorized as Top-0, Top-1, Top-2, and Top-3. The y-axis represents the "F1 Score" ranging from 50 to 80. Four datasets (GSM8k, MATH, OlympiadBench, OmniMATH) are represented by colored bars, and an "Average F1" is shown as a dashed line with markers.
### Components/Axes
**X-axis:**
* **Title:** Number of Retrieval Questions
* **Categories:** Top-0, Top-1, Top-2, Top-3
**Y-axis:**
* **Title:** F1 Score
* **Scale:** 50, 55, 60, 65, 70, 75, 80
**Legend:**
Located in the top-left quadrant of the chart.
* **Dataset:**
* GSM8k (light gray)
* MATH (light blue)
* OlympiadBench (teal green)
* OmniMATH (orange)
* **Average F1:** (black dashed line with black circular markers)
### Detailed Analysis or Content Details
**Top-0:**
* **GSM8k:** 65.60 (light gray bar)
* **MATH:** 67.50 (light blue bar)
* **OlympiadBench:** 55.80 (teal green bar)
* **OmniMATH:** 50.90 (orange bar)
* **Average F1:** 59.80 (black marker on dashed line)
**Top-1:**
* **GSM8k:** 70.50 (light gray bar)
* **MATH:** 72.60 (light blue bar)
* **OlympiadBench:** 60.80 (teal green bar)
* **OmniMATH:** 56.90 (orange bar)
* **Average F1:** 65.50 (black marker on dashed line)
**Top-2:**
* **GSM8k:** 74.90 (light gray bar)
* **MATH:** 71.20 (light blue bar)
* **OlympiadBench:** 59.80 (teal green bar)
* **OmniMATH:** 54.40 (orange bar)
* **Average F1:** 65.50 (black marker on dashed line)
**Top-3:**
* **GSM8k:** 72.30 (light gray bar)
* **MATH:** 71.60 (light blue bar)
* **OlympiadBench:** 57.30 (teal green bar)
* **OmniMATH:** 56.70 (orange bar)
* **Average F1:** 64.50 (black marker on dashed line)
### Key Observations
* **GSM8k and MATH datasets consistently show higher F1 scores** compared to OlympiadBench and OmniMATH across all categories of retrieval questions.
* **The MATH dataset generally performs slightly better than GSM8k** for Top-0 and Top-1 retrieval questions, but GSM8k slightly outperforms MATH for Top-2 and Top-3.
* **OlympiadBench and OmniMATH datasets exhibit significantly lower F1 scores** throughout. OmniMATH's scores are the lowest among all datasets.
* **The Average F1 score increases from Top-0 to Top-1, then slightly decreases for Top-2 and Top-3.**
* **For Top-0, the Average F1 score is approximately 59.80.**
* **For Top-1, the Average F1 score is approximately 65.50.**
* **For Top-2, the Average F1 score is approximately 65.50.**
* **For Top-3, the Average F1 score is approximately 64.50.**
* The F1 scores for GSM8k and MATH show a general upward trend from Top-0 to Top-2, with a slight dip for GSM8k at Top-3.
* The F1 scores for OlympiadBench and OmniMATH show a general downward trend from Top-0 to Top-3, with a slight increase for OmniMATH at Top-3.
### Interpretation
This chart demonstrates the performance of different datasets in a retrieval task, measured by the F1 score, as the number of retrieval questions increases. The data suggests that the **GSM8k and MATH datasets are more robust and performant** in this retrieval context, likely due to their nature or the way they are structured for such tasks. The **OlympiadBench and OmniMATH datasets appear to struggle more**, indicating potential limitations in their suitability or representation for this specific retrieval scenario.
The trend of the **Average F1 score peaking at Top-1 and Top-2** suggests that there might be an optimal number of retrieval questions for achieving the best overall performance. The subsequent slight decline at Top-3 could indicate diminishing returns or increased complexity that negatively impacts the average performance.
The relative performance of GSM8k and MATH across different "Top-k" categories suggests that while both are strong, there might be subtle differences in how they handle increasing numbers of potential matches. The consistent decline in performance for OlympiadBench and OmniMATH as more retrieval questions are considered highlights a potential weakness in their ability to generalize or maintain accuracy under increased search scope. This could imply that these datasets are either less discriminative or that the models trained on them are less capable of filtering relevant information from a larger pool.